17. Annexe : Introduction aux gestionnaires de versions#
Dans ce chapitre, nous proposons une introduction aux gestionnaires de versions, des outils importants pour les développeurs, qu’ils travaillent seuls ou en équipe. Nous verrons le principe de fonctionnement général dans une première partie. Dans la deuxième séquence, nous configurerons l’environnement qui vous permettra de travailler avec Git sur votre machine dans Eclipse et de vous synchroniser avec le GitLab du CNAM. Enfin, nous verrons les commandes de base pour que vous puissiez utiliser Git (prononcé « guite »).
Notre présentation de Git est ici volontairement restrictive. Git est un gestionnaire de versions très puissant et complexe, nous essayons de le rendre accessible à des développeurs débutants. En particulier, il est possible de se passer de l’intégration de git dans Éclipse et d’utiliser la ligne de commande, mais cet usage est à réserver à des utilisateurs plus avertis.
S1 : Principe de fonctionnement d’un gestionnaire de versions#
Note
Des anciennes diapos sont encore disponibles, elles présentent le fonctionnement de Subversion, un gestionnaire de versions différent de Git. Elles ne collent donc plus au cours présenté mais peuvent intéresser des élèves. Introduction rapide à SVN
Un « gestionnaire de versions » ou « logiciel de contrôle de versions » est destiné, comme son nom l’indique, à gérer les différentes versions de fichiers. Cela va donc nous permettre, en tant que développeur, de pouvoir garder une trace des modifications successives effectuées sur un projet pour le mener à bien.
En effet, dès qu’un projet informatique dépasse quelques dizaines de lignes de code, il devient évident qu’il faut le structurer en plusieurs fichiers, voire en une arborescence complexe, afin que toutes les personnes impliquées puissent comprendre rapidement quelle est la structure du projet et où se trouvent les portions de code relatives à tel ou tel aspect (cf par exemple l’architecture MVC présentée dans le chapitre Modèle-Vue-Contrôleur (MVC)).
Que l’on soit seul ou plusieurs centaines de développeurs sur le même projet, il arrive alors fréquemment que l’on rencontre les problèmes suivants :
un fichier comportant du code fonctionnel a été modifié à un moment et ne fonctionne plus ;
on a ajouté de nouveaux fichiers au projet mais quelques jours/semaines plus tard, on ne se souvient pas pourquoi ;
on a résolu un problème il y a 3 mois dans une partie du code et on aimerait pouvoir réutiliser la solution dans une autre partie du code ;
on souhaite pouvoir travailler à plusieurs endroits (sur plusieurs machines) sans devoir s’envoyer la totalité du code par mail sous forme d’archive ;
on souhaite pouvoir collaborer (pendant que l’un travaille sur la partie modèle, un autre se charge d’améliorer la vue).
Un gestionnaire de versions comme Git va permettre de résoudre ces situations problématiques En effet, les développeurs du projet pourront:
garder une trace des modifications faites sur chaque fichier avec des commentaires associés,
pouvoir facilement revenir à un état antérieur du code
fusionner efficacement les modifications de plusieurs personnes pour avoir une version cohérente du code.
Les dépôts et les commits#
À la base d’un gestionnaire de versions, il y a ce qu’on appelle un « dépôt » (en anglais repository). Il s’agit, en première approximation, d’un dossier dans lequel vous allez travailler et décider que tout ce qui se trouvera dans ce dossier sera sous le contrôle de Git.
Note
Quand on travaillera en synchronisation avec la plateforme GitLab, on effectuera en réalité la synchronisation de deux dépôts, celui sur notre machine et celui sur la plateforme (qui servira donc notamment de copie de sauvegarde, en cas de problème sur votre machine principale). De même, si vous travaillez sur plusieurs machines, pour démarrer sur une nouvelle machine il vous suffira de créer un dépôt et de le synchroniser avec celui du Gitlab pour revenir immédiatement à la dernière modification faite sur votre code.
Deuxième aspect important, la notion de révision, ou de commit (selon le gestionnaire utilisé). Il s’agit d’un état de l’arborescence à un moment donné. Git ne fera pas d’enregistrement automatique de vos fichiers : il va falloir lui indiquer, précisément, le moment où vous souhaitez enregistrer un état de votre code, avec un message de commit qui vous permettra plus tard de comprendre quel était l’état du code à ce moment-là. Voici des exemples de messages pour divers projets : « ajout d’une page de contact sur le site », « résolution du bug sur le bouton de validation de panier dans la page de Commande », « la communication avec la base de données a été établie et fonctionne. ». Chaque commit se voit attribuer un identifiant automatique par Git, de façon à ce qu’il soit unique au sein d’un projet. Plus tard, vous pourrez voir l’arborescence de votre projet comme sur la figure Historique Git, qui montre une partie du code destiné à ce cours, avec les différents messages de commit que j’ai utilisés.
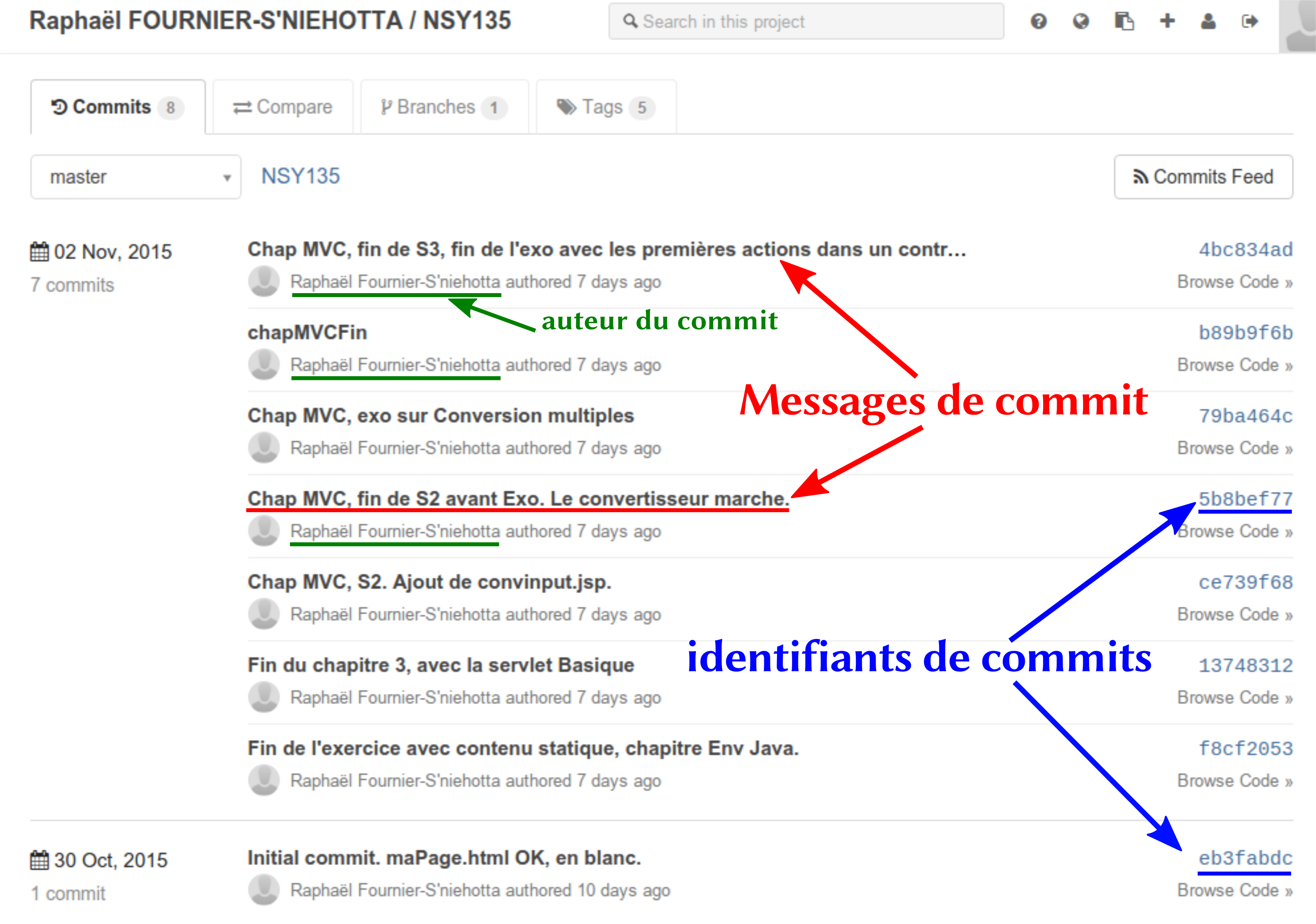
Figure 1: Historique Git#
À l’aide de l’identifiant, il sera ensuite facile d’indiquer à Git à quel moment de l’historique on souhaite revenir. Ou d’identifier à quel moment a été introduite telle ou telle modification.
Note
Même si ce n’est pas toujours immédiatement apparent, chaque commit est aussi signé avec le nom et l’adresse mail de son auteur. Donc il est possible de savoir non seulement quand a été introduit un bug, mais aussi de savoir qui est à l’origine du commit posant problème.
Un système décentralisé#
Nous allons maintenant expliquer l’aspect décentralisé de GIT à partir de la figure Le système décentralisé avec le GitLab du Cnam. Cette figure montre l’organisation que nous allons adopter avec l’environnement proposé par le Cnam.
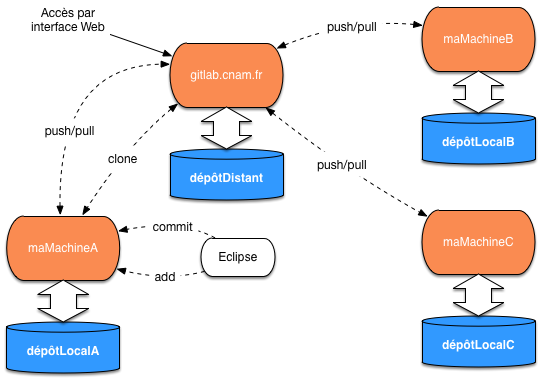
Figure 2: Le système décentralisé avec le GitLab du Cnam#
Pour commencer regardons en bas à gauche. Nous avons une machine maMachineA sur laquelle
nous développons notre projet avec Eclipse. les fichiers de ce projet sont gérés par
un GIT qui entrepose les versions successives dans un dépôt local. Ici, il se nomme
dépôtLocalA.
Chaque fois que nous effectuons une mise à jour d’un fichier avec Eclipse, nous avons la possibilité de le sauvegarder dans le dépôt local. Nous avons en fait deux commandes:
addpermet d’ajouter un nouveau fichier;
commitpermet de valider les modifications sur un fichier.
Il y a d’autres commandes, et notamment celles qui permettent de revenir à une version antérieure si on a fait une erreur. mais pour l’instant nous allons nous contenter de ces deux-là.
Maintenant, notre dépôt GIT est local ce qui n’est pas très pratique. D’une part si nous n’avons plus accès
à notre machineA, nous ne pouvons plus accéder à nos fichiers, d’autre part nous ne pouvons pas
travailler avec d’autres personnes en partageant des fichiers.
Nous allons donc synchroniser notre dépôt local avec un dépôt distant. En langage GIT, cela
s’appelle clôner des dépots. GIT étant entièrement décentralisé, on peut se clôner avec
plusieurs autres dépôts dans le cas très général. Mais dans notre cas particulier, nous allons
toujours nous clôner avec le dépôt du CNAM, qui est nommé dépôtDistant sur la figure.
Pour clôner deux dépôts, on utilise initialement la commande GIT clone. Les deux dépôts
sont alors connnectés et synchronisés.
Ensuite, chacun va vivre sa vie. Des modifications seront faites sur le dépôt local, d’autres sur le dépôt distant. À un moment donné on va vouloir synchroniser, dans un sens ou dans les deux sens. Supposons que l’on soit situé au niveau du dépôt local, alors: GIT sont les suivantes:
pushva transmettre les modifications du dépôt local vers le dépôt distant;
pullva transmettre les modifications du dépôt distant vers le dépôt local.
Et voilà! Il y a beaucoup d’autres choses (des branches, et autres complications) mais cela va nous suffire: quand nous maîtriserons ces commandes, nous serons déjà satisfaits.
Une simple remarque pour finir: supposons que machineA est celle que vous utilisez au Cnam. Vous
rentrez chez vous après avoir synchronisé vos fichiers avec le dépôt distant, et vous voudriez
continuer à travailler sur votre machineB en récupérant toutes vos mises à jour.
Vous voyez peut-être comment faire? Il suffit de clôner le dépôt distant avec votre nouveau dépôt local, celui de la machineB, et le tour est joué: vous retrouvez tout votre environnement de travail.
C’est déjà très bien comme cela. Passons à la pratique.
S2 : Ce qu’il faut savoir faire#
Dans cette section nous allons effectuer les principales manipulations avec Git, celles que vous serez amenés à faire régulièrement pour gérer votre projet. Les voici, en résumé.
Créer votre dépôt distant Git sur l’environnement du Cnam.
Clôner le dépôt distant vers votre dépôt local.
Créer un projet avec Eclipse, et placer les fichiers du projet sous le contrôle Git du dépôt local.
Synchroniser le dépôt local et le dépôt distant.
Enfin, installer votre projet sur une nouvelle machine en clônant le dépôt distant.
À ce stade, vous devriez comprendre le but de ces manipulations. Prenez le temps de bien relire ce qui précède et de réfléchir à l’utilité de ce que nous allons faire : il s’agit tout simplement de votre capacité à pouvoir travailler sur votre projet avec n’importe quelle machine, en utilisant un dépôt Git distant comme pivot pour récupérer vos fichiers.
Le dépôt distant: le GitLab du Cnam#
Le CNAM a mis en place une plateforme en ligne reposant sur le logiciel GitLab afin de permettre aux étudiants de déposer leur projets gérés par Git. Vous devriez être en mesure de vous connecter à cette plateforme à l’aide de vos identifiants traditionnels. L’interface est en anglais, mais nous allons la présenter pour que vous puissiez retrouver rapidement vos projets et naviguer au sein de chacun.
La plateforme GitLab du CNAM est accessible via l’adresse suivante : https://gitlab.cnam.fr. En cliquant sur le lien précédent, vous devriez arriver sur l’écran Login sur Gitlab.
Figure 3: Login sur Gitlab#
Après saisie de vos identifiants, vous devriez ensuite arriver sur un écran pour le moment assez vide (il sera plus tard dédié à la visualisation de l’activité dans votre projet, comme on le verra plus loin). En haut à droite de l’écran, se trouvent deux boutons pour créer un nouveau projet, l’un en forme de croix, l’autre en vert et portant la mention « New project », comme sur la figure Créer un nouveau projet.
Important
Cette mention « project » signifie ici « dépôt » : vous allez créer un dépôt, qui sera plus tard synchronisé avec les sources de votre projet sur votre machine. Ce n’est pas très heureux de donner des noms différents à un même concept mais nous n’y pouvons rien.
Figure 4: Créer un nouveau projet#
Cliquer sur l’un de ces boutons vous amène à un écran où vous définirez quelques paramètres pour votre nouveau projet (cf Figure Paramètres pour un nouveau projet) :
un nom (très important)
un niveau de visibilité (choisissez « Private », de façon que votre travail ne soit, ici, pas visible des autres).
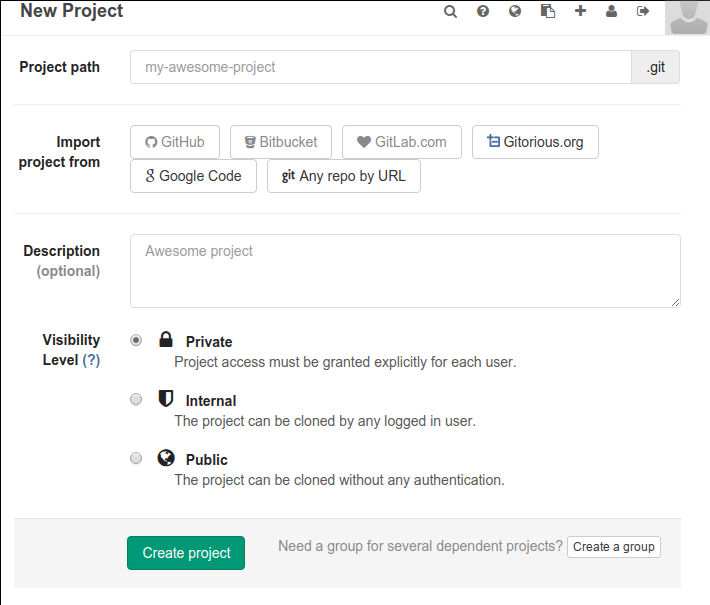
Figure 5: Paramètres pour un nouveau projet#
Vous devriez aboutir à un écran qui vous donne notamment l’URL pour synchroniser le travail entre votre machine et la plateforme Gitlab (il faut cliquer sur le bouton HTTPS, plutôt que SSH).
Exemple
Le projet des enseignants a pour URL https://gitlab.cnam.fr/gitlab/NSY135-profs/NSY135.git
Exercice.
Connectez-vous à gitlab et créez votre dépôt (projet) NSY135.
Clôner le dépôt distant vers le dépôt local#
Maintenant nous allons clôner le dépôt distant vers le dépôt local. Il faut pour cela effectuer des commandes Git. On peut le faire en ligne de commande, mais on peut aussi utiliser Eclipse. Pour cela, nous allons devoir recourir à l’utilisation d’un plugin, très bien fait, qui permettra d’interagir avec le dépôt local et le dépôt distant sans utiliser la ligne de commande.
Quand le plugin est installé, il est possible avec Eclipse d’accéder à la perspective GIT. C’est celle qui va nous permettre de gérer les dépôts. Dans le menu Window -> Open Perspective, vérifier que vous pouvez ouvrir cette perspective. Si ce n’est pas le cas il faut installer le plugin.
Note
Les nouvelles versions d’Éclipse intègrent Git de façon native (sans plugin). J’utilise Eclipse 4.5.0, sortie en juin 2015.
Dans Éclipse, allez dans le menu « Aide » et cliquez sur « Installez de nouveaux logiciels et composants ». Dans le premier champ, entrez l’URL « http://download.eclipse.org/egit/updates » et cliquez sur Ajouter. Vous devriez ensuite être en mesure de cocher « Eclipse Git Team Provider » et de cliquer sur « Suivant » (cf figure Ajout du site pour télécharger Eclipse Git Team Provider). Poursuivez ensuite l’installation et redémarrez Éclipse pour que les changements soient pris en compte.
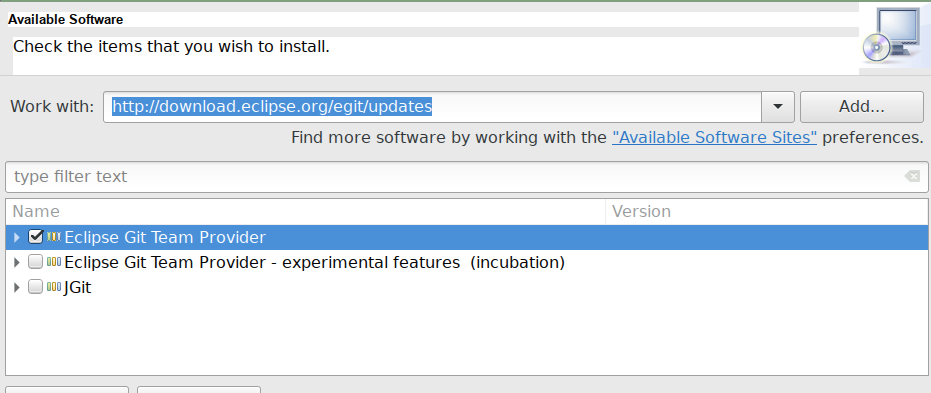
Figure 6: Ajout du site pour télécharger Eclipse Git Team Provider#
Une fois le plugin installé, vous verrez une fenêtre semblable à celle de la figure La perspective Git dans Eclipse. Sur la gauche, nous voyons la liste des dépôts locaux qui sont connus d’Eclipse. Ici, nous en voyons deux. L’arborescence du premier a été déployée: vous pouvoir voir des Branches, des tags, un Working tree qui contient un répertoire .git avec les informations gérées par Git, et un répertoire NSY135: c’est la version courante des fichiers d’un projet nommé NSY135.
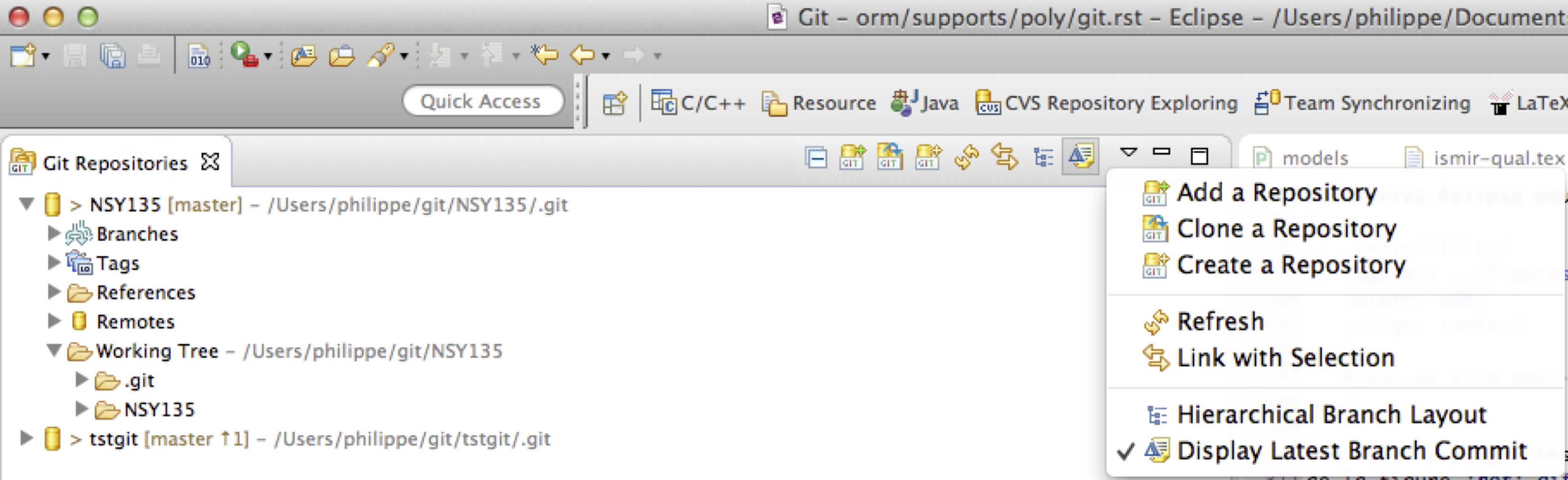
Figure 7: La perspective Git dans Eclipse#
Dans votre cas, il n’y aura sans doute aucun dépôt local. Nous allons donc en créer un. Regardez à nouveau la figure: elle montre un menu sur la droite avec les options de création d’un dépôt. Vous pouvez:
Importer un dépôt local existant mais pas encore connu d’Eclipse
Créer directement un dépôt local avec Eclipse.
Créer un dépôt local par clônage d’un dépôt distant.
C’est cette dernière option que nous allons appliquer: nous allons clôner le dépôt distant du GitLab vers un dépôt local.
La figure Spécifier le dépôt distant à clôner. montre la première fenêtre de clônage. On y entre l’URL HTTPS du dépôt que vous avez créé dans le GitLab.
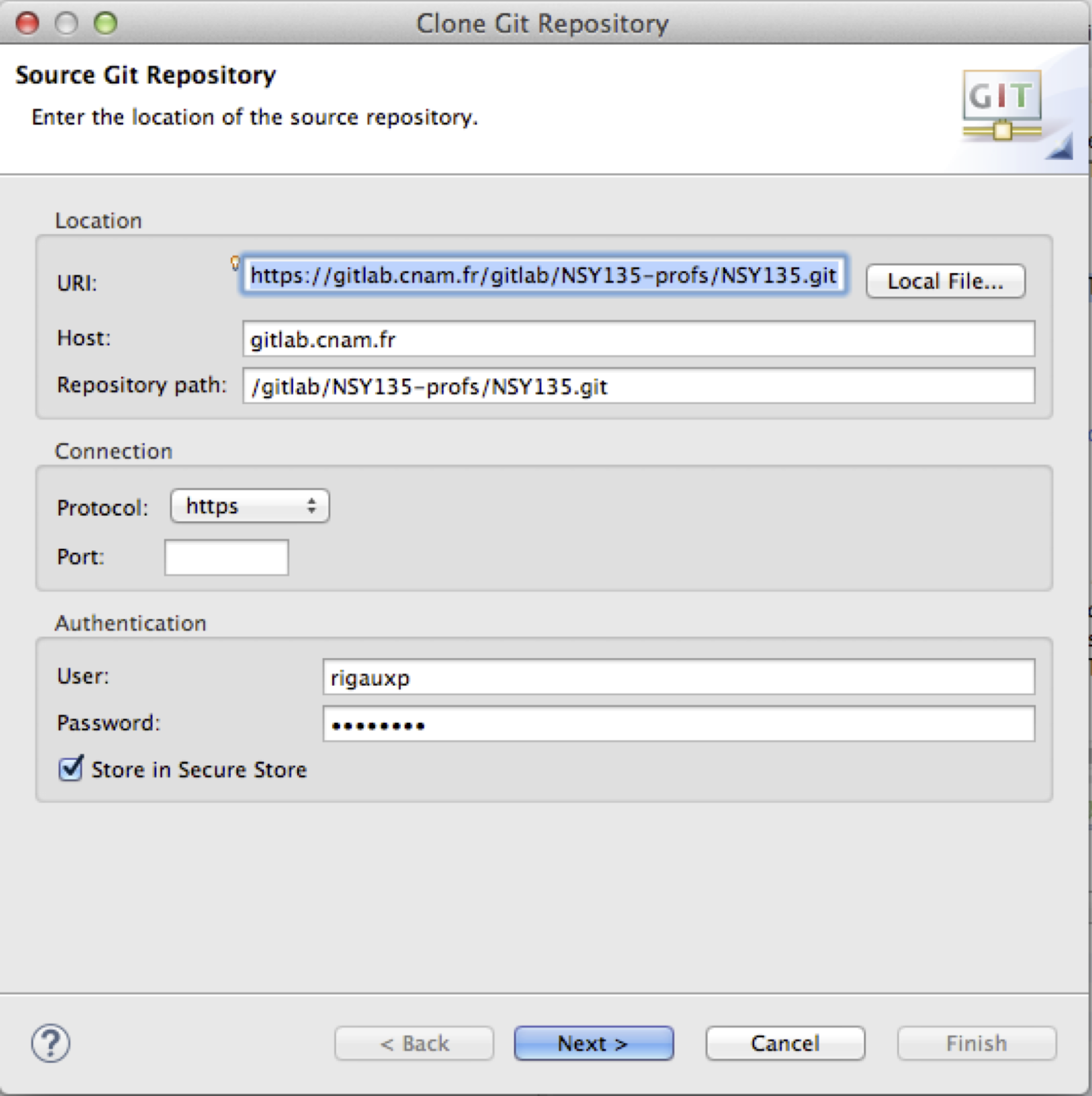
Figure 8: Spécifier le dépôt distant à clôner.#
La fenêtre suivante demande quelle branche vous souhaitez prendre: acceptez
le choix par défaut (master) et passez à la troisième fenêtre
(figure Spécifier le dépôt local.). Vous pouvez choisir le nom du dépôt local
ou reprendre le nom du dépôt distant. Notez que les dépôts locaux sont
placés dans un répertoire sur votre machine dédié à Git (ici, le
répertoire HOME/git.
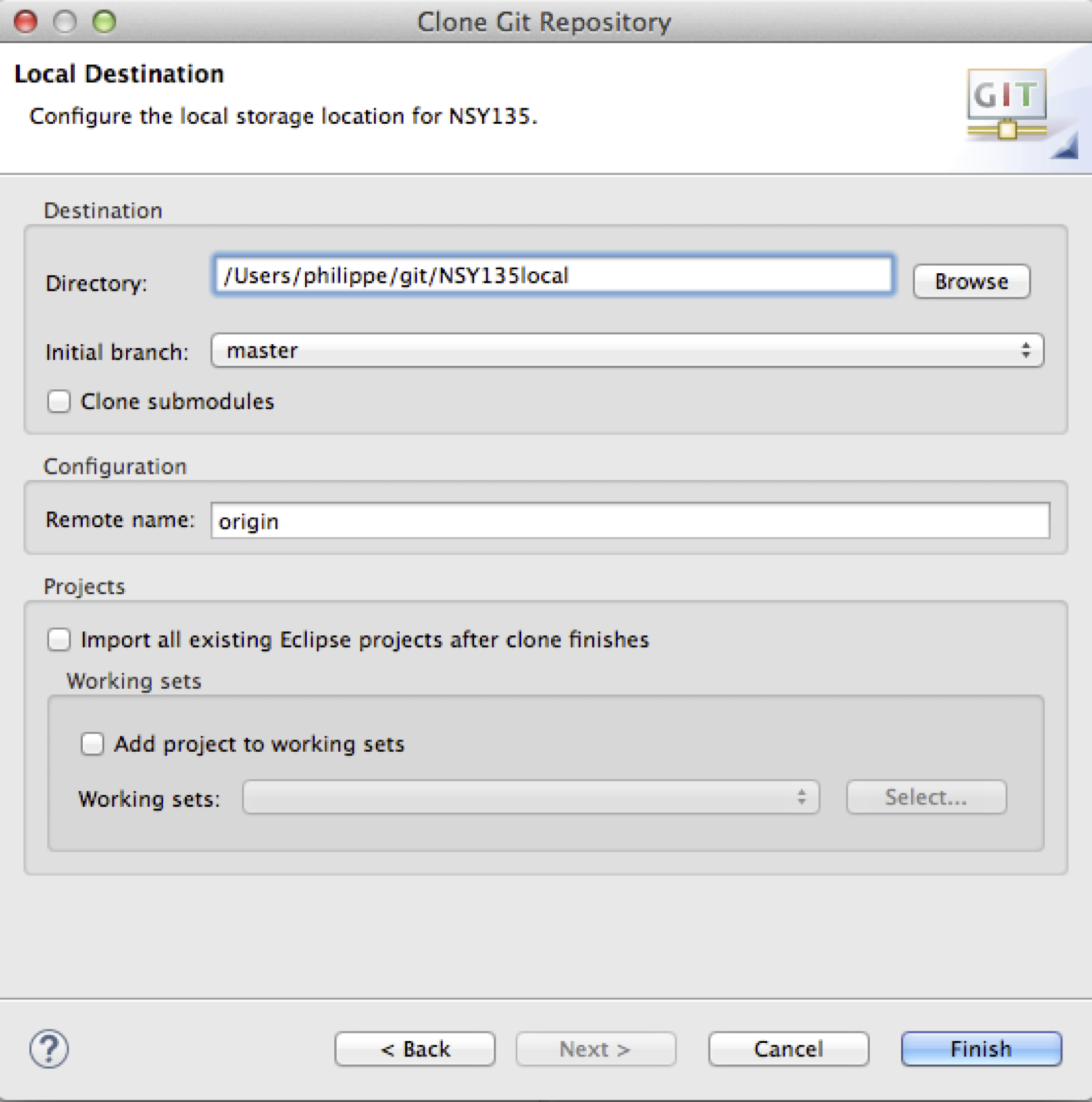
Figure 9: Spécifier le dépôt local.#
Validez: votre dépôt distant sera clôné, et vos deux dépôts (le distant et le local) sont maintenants connectés. En cliquant sur le nom du dépôt qui a dû apparaître dans la fenêtre Git, vous verrez les informations sur cette connexion.
Et voilà! Vos dépôts sont vides: l’étape suivante consiste à commencer à y placer des fichiers.
Gérer votre projet avec Eclipse et GIT#
Créez un projet quelconque dans Eclipse. Ensuite, déclarez que vous souhaitez versionner ce projet (c’est-à-dire le placer sous le contrôle de Git) en utilisant le menu contextuel sur le nom de votre projet (un Dynamic Web Project comme vu dans le chapitre Environnement Java) puis en choisissant « Team » et « Share Project » (plus tard, j’utiliserai la syntaxe Team > Share Project pour désigner cette séquence d’opérations).
Eclipse vous demande dans quel dépôt local vous souhaitez placer votre projet. Choisissez-le et validez. Vous devez voir que votre projet comporte maintenant la mention [Git master] à sa droite et est précédée d’un symbole « > ». Cela signifie que des fichiers existent dans le dossier mais ne sont pas encore géré par Git. C’est parfaitement normal : nous avons dit que nous voulions que ce dossier soit contrôlé par Git, mais nous ne lui avons pas dit que nous voulions qu’il gère absolument tout…
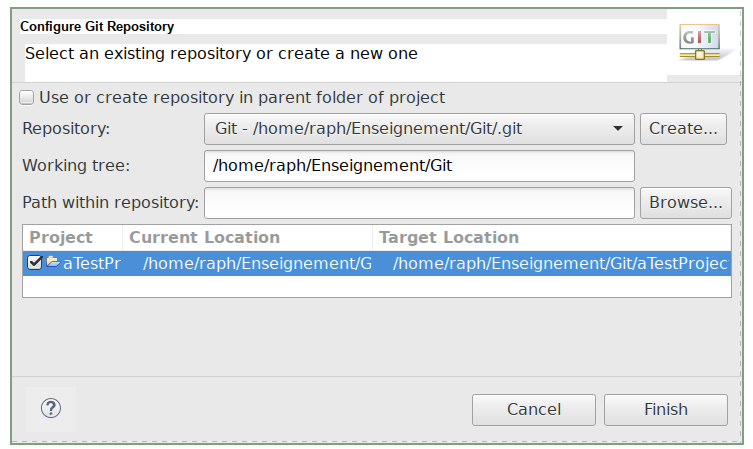
Figure 10: Sélection du dépôt Git sur votre machine.#
Avec le menu contextuel (clic-droit) sur le nom du projet dans l’explorateur (partie gauche de l’interface), vous pouvez voir le menu Team en bas, qui contient les différentes actions liées à Git. Vous pouvez commencer par ajouter l’arborescence actuelle à votre dépôt, en sélectionnant Add to index (cf la figure Ajout de l’arborescence du projet à Git). Cette première opération ne valide pas encore : elle dit simplement que vous préparez votre projet en déclarant ce que vous allez placer sous le contrôle de Git (pour le moment tout, mais comme il n’y a presque rien dans votre projet…).
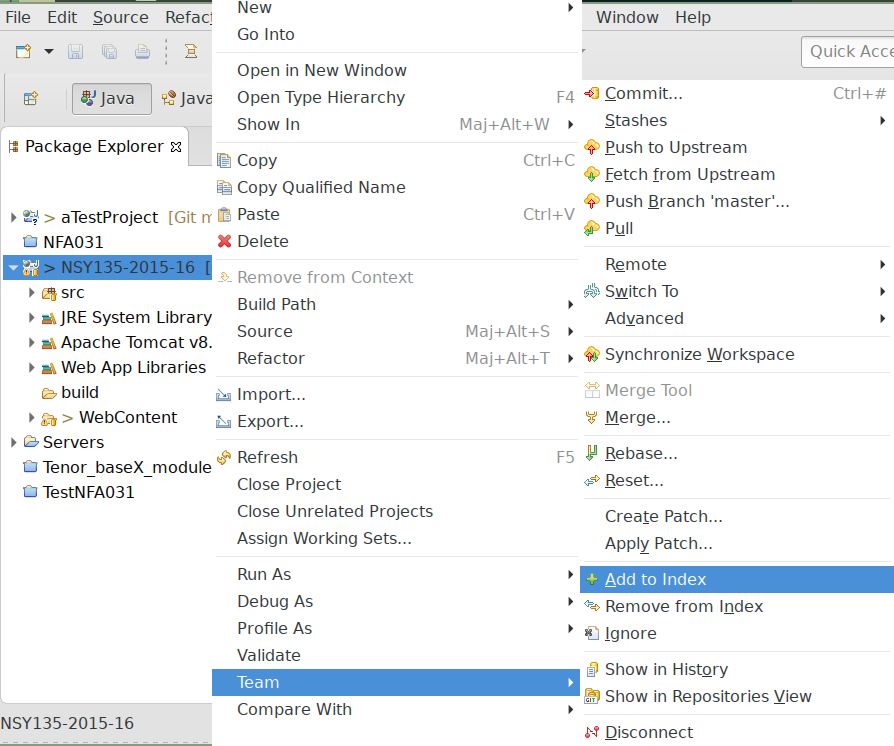
Figure 11: Ajout de l’arborescence du projet à Git#
Il faut ensuite valider ces changements. Dans le langage Git, on parle de commit. Dans le menu Team, optez pour l’option tout en haut, appelée Commit. Une fenêtre s’ouvre et il ne vous reste plus qu’à indiquer un message de commit utile pour valider vos modifications (voir figure Valider un commit en donnant un message d’explication ). Ici, comme c’est le premier message, « Premier commit, initialisation de l’arborescence » est un message suffisant. Validez avec le bouton Commit and push et voilà, vous avez effectué votre premier commit avec Git (le push aura aussi permis de synchroniser avec la plateforme distante).
Plus tard, il faudra que vos messages décrivent quel a été l’apport d’un commit
par rapport à la version précédente, de façon à avoir un historique
compréhensible de la construction de votre projet. Revenez à la figure
histoGit plus haut pour des exemples de messages.
Note
Une bonne pratique pour rédiger ses messages est de décrire « pourquoi » on a introduit telle ou telle modification. Il vaut mieux éviter de s’attarder sur le « quoi », puisque le lecteur intéressé pourra visualiser facilement ce qui a été introduit dans le code (avec git diff, cf section suivante, ou via l’interface Gitlab). Dans les références en fin de chapitre, vous trouverez un article dédié à la rédaction de messages de commit.
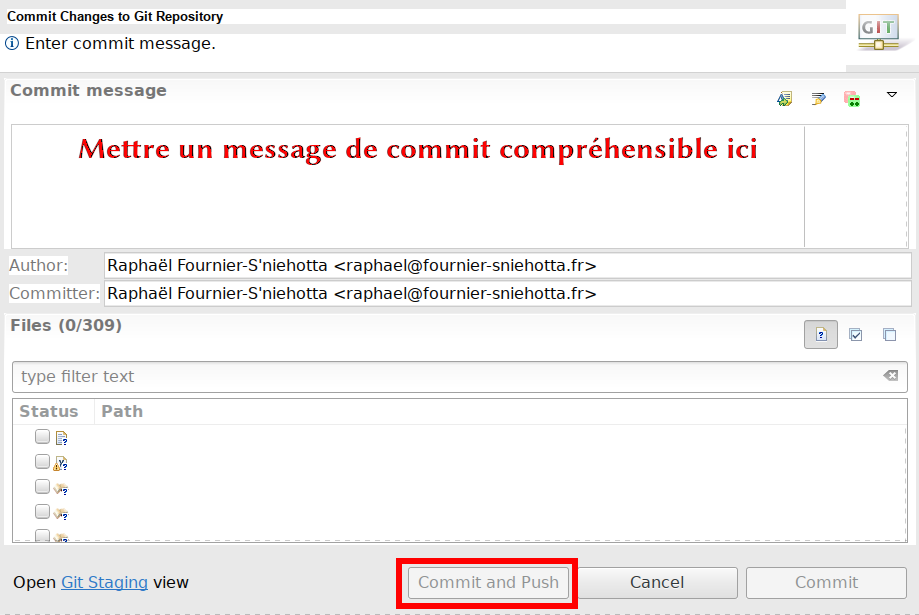
Figure 12: Valider un commit en donnant un message d’explication#
Opérations sur le dépôt local#
Les opérations de base permettent de travailler seul, avec un dépôt distant de sauvegarde. De cette façon, Git sert à enregistrer un historique du travail effectué.
Dans la section précédente, vous avez effectué un premier commit. Le travail ultérieur suivra une procédure similaire :
ajouter du contenu à votre arborescence (écrire du code)
décider de ce que vous souhaitez valider (git add)
valider (git commit)
envoyer votre ou vos commits au dépôt distant (git push)
Le premier point ne dépend pas de Git, seulement de votre éditeur de code. Le deuxième point fait appel à la commande git add, qu’on a utilisé précédemment à l’aide d’une commande graphique, sur la figure Ajout de l’arborescence du projet à Git. Nous avions choisi d’ajouter toute notre arborescence, mais vous pouvez effectuer des ajouts partiels, en ne choisissant qu’un sous-ensemble des dossiers/fichiers présents (en faisant un clic droit sur chacun des sous-dossiers ou des fichiers, puis Add to index).
Note
Remarquons ici que certains fichiers ne seront généralement pas « versionnés », sans quoi cela risquerait de surcharger inutilement le dépôt. Il s’agit notamment des bibliothèques lourdes que vous ajoutez à votre projet, et plus généralement des fichiers binaires (images, exécutables) : Git est, avant tout, fait pour « versionner » du texte (code source).
Vous pouvez utiliser la Git Staging View (vue préparatoire en français), une interface avec laquelle on visualise précisément l’ensemble des fichiers d’un dépôt qui ne seront pas contrôlés par Git, lesquels ont été modifiés depuis le dernier commit et on choisit lesquels seront incorporés au prochain commit (voir exemple figure Git staging : espace pour choisir ce qui sera ou ne sera pas intégré au prochain commit.). Depuis cette interface, vous pouvez aussi accéder à une comparaison entre l’état actuel du fichier et l’un de ses états passés (accessible également via clic-droit > Compare With > Commit…).
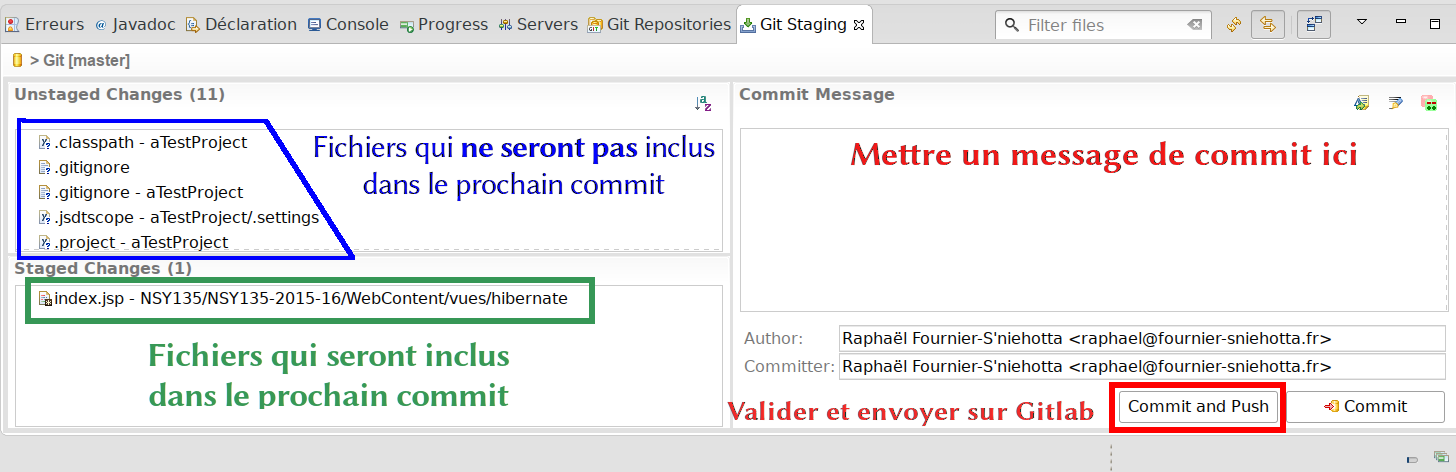
Figure 13: Git staging : espace pour choisir ce qui sera ou ne sera pas intégré au prochain commit.#
Synchroniser avec le dépôt distant#
Une fois que vous êtes satisfait de ce que vous avez réalisé dans l’interface de staging, vous pouvez écrire un joli message de commit dans la partie droite puis cliquer sur Commit and Push (valider et envoyer en français), ce qui permettra d’envoyer votre commit sur le Gitlab configuré précédemment.
Une fois l’opération d’envoi effectuée, vous devriez pouvoir voir les changements sur Gitlab, de façon similaire à ce qui est visible sur la figure Historique Git.
Note
Vous aurez peut-être remarqué qu’il y a le choix entre Commit et Commit and Push. Pour un usage simple et efficace, recourez seulement à Commit and Push. Parfois, vous pouvez avoir besoin de ne pas envoyer tout de suite un ensemble de modifications vers la plateforme, et les conserver sur votre machine, vous utiliserez alors le Commit seul.
Récupérer un projet sur une nouvelle machine#
Maintenant, vous êtes en mesure de travailler, à des moments différents, sur deux machines (typiquement une chez vous et l’autre au CNAM), chacune pouvant envoyer ses changements sur la plateforme distante Gitlab. Il vous manque cependant la possibilité de recevoir les changements effectués sur l’autre machine. En effet, si vous travaillez sur les deux machines à des moments différents, vous allez avoir besoin de récupérer ce qui a été fait sur l’autre machine, pour travailler sur la dernière version et ne pas devoir refaire sur une machine les modifications que vous avez faites sur l’autre.
La première chose à faire quand vous changez de machine est donc, avant toute modification sur votre code, d’utiliser la commande git pull (ou clic-droit > Team > Pull). Cela devrait récupérer sur Gitlab ce que vous avez envoyé avec votre autre machine. Vous pouvez ensuite commencer à travailler, faire des commits et les envoyer.
S3 : Git avancé#
Fonctions avancées#
Note
Avec les fonctionnalités suivantes, on permet le travail collaboratif de plusieurs développeurs. Pour le moment, cette partie n’est pas écrite, l’usage de ces commandes est un peu plus complexe à détailler pour des débutants.
git merge
git diff
git blame
git bisect
git apply (très avancé ?)
Les branches#
Note
De même, l’usage des branches n’est pas encore présenté.
Il est parfois intéressant d’utiliser l’intégration de Git dans Eclipse, mais la ligne de commande permet souvent d’accéder à toute la puissance de Git. Nous allons voir dans cette section une petite démonstration de ce qu’il se passera pour vous quand vous utiliserez Git entre votre machine personnelle et la machine mise à votre disposition pour nos cours au CNAM.
Le scénario que nous illustrons sera le suivant :
un projet de code sera créé durant une séquence introductive en cours, sur une machine du CNAM
le code sera commité et envoyé sur votre espace Gitlab (au moins une fois à la fin de la séance, éventuellement à des moments intermédiaires)
chez vous, le code est récupéré
vous travaillez sur des modifications (exercices, variantes), que vous commitez et envoyez sur Gitlab, de façon à pouvoir les retrouver en cours
la semaine suivante, votre code évolue pour suivre le cours, il est déposé sur Gitlab
et ainsi de suite, vous faites des allers-retours entre vos deux machines de travail.
Nous verrons à la fin que cela peut bien entendu être étendu à plus de deux machines.
Note
Dans cette section, un certain nombre de choses dépendent de votre machine, des choix que vous ferez. J’utilise les symboles < et > pour indiquer ce qui varie. Exemple : si j’écris <votreLogin>, c’est à remplacer par votre login virtualia.
Sur la Machine du CNAM#
On se déplace dans le dossier qui accueillera notre travail, en le créant éventuellement au préalable :
$ mkdir Git/CodeNSY135
$ cd Git/CodeNSY135
On initialise le dépôt Git dans ce dossier :
$ git init
Dépôt Git vide initialisé dans <cheminDuDossier>/.git
On regarde ce qu’il se passe (la commande git status est très importante pour savoir dans quel état est le dépôt). On n’a pour le moment rien fait, git nous l’indique :
$ git status
Sur la branche master
Validation initiale
rien à valider (créez/copiez des fichiers et utilisez "git add" pour les suivre)
On crée un premier fichier de code. J’utilise vim, un éditeur un peu particulier, vous pouvez en utiliser d’autres, comme gedit, kate, nano (installés au CNAM). Sur vos machines, vous pouvez bien sûr utiliser encore autre chose, comme SublimeText, Notepad++, etc.
$ vim maPremiereJsp.jsp // ou gedit maPremiereJsp.jsp
Après avoir fini l’édition d’un fichier, regardons ce que Git sait de notre dépôt :
$ git status
Sur la branche master
Validation initiale
Fichiers non suivis:
(utilisez "git add <fichier>..." pour inclure dans ce qui sera validé)
maPremiereJsp.jsp
aucune modification ajoutée à la validation mais des fichiers non suivis sont présents (utilisez "git add" pour les suivre)
Pour le moment, il n’y a pas encore eu de commit, mais il y a des fichiers présents (en réalité, un seul, maPremiereJsp.jsp) dans le dossier qui ne sont pas dans l’index de git, ils sont « non suivis ». Pour l’ajouter, comme le suggère git, on utilise la commande suivante :
$ git add maPremiereJsp.jsp
Regardons l’état de notre dépôt (vous devriez observer un changement de couleur, le nom du fichier qui était rouge doit passer au vert) :
$ git status
Sur la branche master
Modifications qui seront validées :
(utilisez "git reset HEAD <fichier>..." pour désindexer)
nouveau fichier : maPremiereJsp.jsp
Nous pouvons maintenant valider nos changements, avec un message de commit expliquant ce qu’on vient de faire.
$ git commit
<ouverture de vim>
<saisir le message de commit, en appuyant d'abord sur "i" pour entrer dans le
mode Insertion, et en terminant par Échap, ":wq" pour quitter et valider le
message de commit>
[master (commit racine) 489c500] <Premier commit.>
1 file changed, 15 insertions(+)
create mode 100644 maPremiereJsp.jsp
J’ai saisi un message de commit simple, « Premier commit. ». Si je regarde l’état du dépôt, il est considéré comme « propre » :
$ git status
Sur la branche master
rien à valider, la copie de travail est propre
En utilisant la commande git log, on peut retracer les différents commits, avec leurs auteurs et la date précise de leur validation :
$ git log
commit 489c500ebac812873fe4595c034b53fc89ca8e76
Author: Raphaël Fournier-S'niehotta <raphael@fournier-sniehotta.fr>
Date: Tue Mar 15 14:54:58 2016 +0100
Premier commit.
Vous pouvez refaire cette séquence d’opérations (ajouter du code, valider les changements quand c’est satisfaisant) plusieurs fois consécutivement. Il est ensuite temps d’envoyer ce code sur Gitlab, pour synchroniser notre dépôt avec la plateforme et pouvoir simplement le récupérer sur une machine chez nous.
Une fois que vous aurez créé le projet et renseigné son nom (cf figures Créer un nouveau projet et Paramètres pour un nouveau projet ci-dessus), vous arriverez sur une page comme sur la figure newProjectOKGitlab. Cette fois, vous allez utiliser les commandes du bas de la page :
$ git remote add origin <VotreURLdeProjet>
$ git push -u origin master
Username for 'https://gitlab.cnam.fr': <VotreLogin>
Password for 'https://<votreLogin>@gitlab.cnam.fr': <VotrePassword>
Décompte des objets: 3, fait.
Delta compression using up to 4 threads.
Compression des objets: 100% (2/2), fait.
Écriture des objets: 100% (3/3), 468 bytes | 0 bytes/s, fait.
Total 3 (delta 0), reused 0 (delta 0)
To https://gitlab.cnam.fr/gitlab/fournier/demoProject.git
* [new branch] master -> master
La branche master est paramétrée pour suivre la branche distante master
depuis origin.
Et voilà, la synchronisation pourra s’effectuer maintenant vers Gitlab. En allant sur la plateforme, vous devriez voir quelque chose qui ressemble à la figure Vue du projet sur Gitlab après un premier commit synchronisé. ci-dessous.
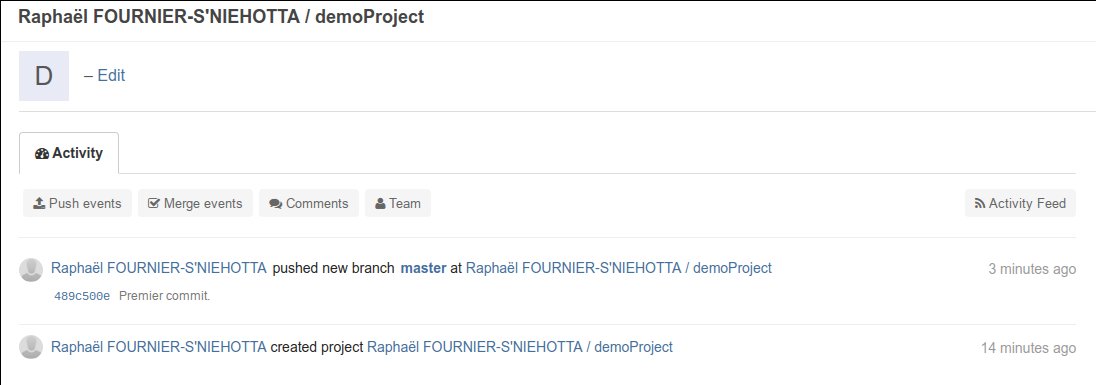
Figure 14: Vue du projet sur Gitlab après un premier commit synchronisé.#
Après l’exercice, il est maintenant temps de passer à la configuration de votre machine personnelle.
Exercice: Envoyer un second commit
Reprenez les opérations d’écriture de fichier, d’ajout à l’index et de validation du commit avec un nouveau fichier, maDeuxiemeJsp.jsp. Synchronisez avec Gitlab (en utilisant la commande git push après avoir commité). Regardez dans l’interface Gitlab l’apparition de vos changements, d’abord sur comme sur la figure précédente, puis en explorant les différents onglets dans le menu de gauche : « Files », « Commits », « Network », « Graphs ».
Chez vous#
Sur cette nouvelle machine, vous souhaitez récupérer le code que vous avez envoyé sur Gitlab. Vous ne partez donc pas « de rien », mais d’une synchronisation avec un dépôt existant.
Si vous n’avez pas encore complètement configuré Git, il se peut qu’il vous soit demandé de saisir votre nom et votre adresse mail. Voici un exemple :
git config --global user.name "<votre nom complet>"
git config --global user.email "<votre adresse mail>"
Ensuite, placez-vous dans un dossier dans lequel vous voulez créer le dossier du dépôt (par exemple : ~/CoursCNAM/NSY135). La récupération du dépôt va se faire en utilisant la commande git clone, comme suit (l’url étant bien sûr celle que vous obtenez pour votre projet sur la plateforme, cf figure newProjectOKGitlab) :
$ git clone https://gitlab.cnam.fr/gitlab/fournier/demoProject.git
Clonage dans 'demoProject'...
Username for 'https://gitlab.cnam.fr': fournier
Password for 'https://fournier@gitlab.cnam.fr':
remote: Counting objects: 3, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 0), reused 0 (delta 0)
Dépaquetage des objets: 100% (3/3), fait.
Vérification de la connectivité... fait.
Vous pouvez ensuite entrer dans le dossier et regarder où il en est :
$ cd demoProject
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
rien à valider, la copie de travail est propre
$ git log
commit 489c500ebac812873fe4595c034b53fc89ca8e76
Author: Raphaël Fournier-S'niehotta <raphael@fournier-sniehotta.fr>
Date: Tue Mar 15 14:54:58 2016 +0100
Premier commit.
Vous retrouvez ici votre projet dans lequel vous l’avez laissé.
Écrivons un nouveau fichier, correspondant à une nouvelle vue pour notre projet :
$ vim maJspJolie.jsp
Une fois que c’est fait, vous obtenez ce qu’on avait vu auparavant, c’est-à-dire un état où il y a des fichiers dans le dossier qui ne sont pas sous le contrôle de Git.
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
Fichiers non suivis:
(utilisez "git add <fichier>..." pour inclure dans ce qui sera validé)
maJspJolie.jsp
aucune modification ajoutée à la validation mais des fichiers non suivis sont présents (utilisez "git add" pour les suivre)
Évidemment, il faut ensuite ajouter et valider ce changement :
$ git add maJspJolie.jsp
$ git commit
[master 014416e] Deuxième commit, avec une nouvelle vue.
1 file changed, 15 insertions(+)
create mode 100644 maJspJolie.jsp
Maintenant, un git status nous informe :
$ git status
Sur la branche master
Votre branche est en avance sur 'origin/master' de 1 commit.
(utilisez "git push" pour publier vos commits locaux)
rien à valider, la copie de travail est propre
Nous avons effectué des changements locaux, mais ils n’ont pas encore été publiés sur Gitlab : pour le moment, Gitlab est toujours dans l’état dans lequel vous l’avez laissé en quittant votre machine CNAM la dernière fois (si vous n’êtes pas convaincus, allez vérifier sur la plateforme). Vous pouvez bien sûr effectuer plusieurs commits successifs sans envoyer les changements. Mais, si vous voulez pouvoir réutiliser votre code au CNAM la prochaine fois, il va vous falloir « pousser » (soumettre) vos commits à Gitlab, comme suit :
$ git push
Username for 'https://gitlab.cnam.fr': fournier
Password for 'https://fournier@gitlab.cnam.fr':
Décompte des objets: 3, fait.
Delta compression using up to 4 threads.
Compression des objets: 100% (3/3), fait.
Écriture des objets: 100% (3/3), 543 bytes | 0 bytes/s, fait.
Total 3 (delta 0), reused 0 (delta 0)
To https://gitlab.cnam.fr/gitlab/fournier/demoProject.git
489c500..014416e master -> master
$ git status
Sur la branche master
Votre branche est à jour avec 'origin/master'.
rien à valider, la copie de travail est propre
Le log vous affiche donc un deuxième commit :
$ git log
commit 014416ec7a561387a63481f75eefff01af69865f
Author: Raphaël Fournier-S'niehotta <raphael@fournier-sniehotta.fr>
Date: Tue Mar 15 16:11:20 2016 +0100
Deuxième commit, avec une nouvelle vue.
commit 489c500ebac812873fe4595c034b53fc89ca8e76
Author: Raphaël Fournier-S'niehotta <raphael@fournier-sniehotta.fr>
Date: Tue Mar 15 14:54:58 2016 +0100
Premier commit.
Sur la plateforme, vous devriez maintenant voir votre commit apparaître (rechargez éventuellement la page).
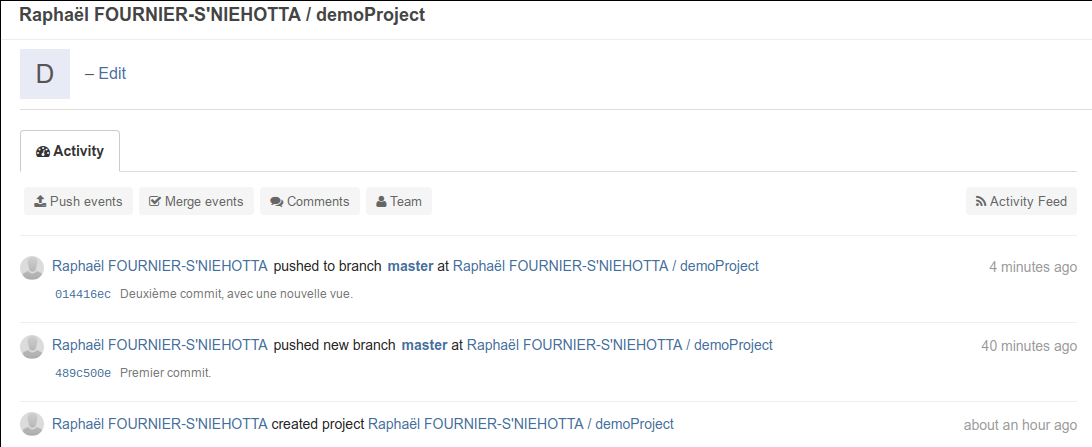
Figure 15: Vue du projet sur Gitlab après un deuxième commit, effectué depuis une nouvelle machine.#
Voilà, vous pouvez continuer à travailler sur cette machine, en pensant bien à envoyer vos commits une fois que vous avez terminé, pour que vous puissiez récupérer tout cela en salle de cours.
De retour au CNAM#
Quand vous arrivez dans la salle du CNAM pour débuter un nouveau cours, si vous avez effectué des modifications chez vous, elles ont été synchronisées avec Gitlab, mais pas avec le dépôt local sur votre machine du CNAM. Il est donc fondamental de commencer par remettre à jour la version locale de votre dépôt avec celle de Gitlab.
Pour vous en convaincre, regardez avec git log:
$ git log
commit 489c500ebac812873fe4595c034b53fc89ca8e76
Author: Raphaël Fournier-S'niehotta <raphael@fournier-sniehotta.fr>
Date: Tue Mar 15 14:54:58 2016 +0100
Premier commit.
Pour effectuer cette synchronisation, vous allez utiliser la commande git pull :
$ git pull
Username for 'https://gitlab.cnam.fr': fournier
Password for 'https://fournier@gitlab.cnam.fr':
remote: Counting objects: 3, done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 0 (delta 0)
Dépaquetage des objets: 100% (3/3), fait.
Depuis https://gitlab.cnam.fr/gitlab/fournier/demoProject
489c500..014416e master -> origin/master
Mise à jour 489c500..014416e
Fast-forward
maJspJolie.jsp | 15 +++++++++++++++
1 file changed, 15 insertions(+)
create mode 100644 maJspJolie.jsp
Celle-ci vous indique de nombreuses informations sur les téléchargements qu’elle effectue afin de synchroniser les versions. Vous obtenez ainsi un dépôt qui contient aussi vos modifications « de chez vous » :
$ git log
commit 014416ec7a561387a63481f75eefff01af69865f
Author: Raphaël Fournier-S'niehotta <raphael@fournier-sniehotta.fr>
Date: Tue Mar 15 16:11:20 2016 +0100
Deuxième commit, avec une nouvelle vue.
commit 489c500ebac812873fe4595c034b53fc89ca8e76
Author: Raphaël Fournier-S'niehotta <raphael@fournier-sniehotta.fr>
Date: Tue Mar 15 14:54:58 2016 +0100
Premier commit.
Vous pouvez ensuite travailler, ajouter du code, valider (git add et git commit) et envoyer sur Gitlab (git push).
De retour chez vous#
Maintenant que la synchronisation a été mise en place, votre machine doit normalement être en mesure de récupérer les modifications effectuées ailleurs à l’aide d’un git pull.
À retenir de cette séquence#
Après la phase de configuration des machines, la séquence de travail est toujours :
git pull
écrire du code
git add <fichiers modifiés>
git commit
écrire du code
git add <fichiers modifiés>
git commit
git push
N’oubliez ni le pull initial, ni le push final !
Références pour aller plus loin#
La référence reste les pages de man (sous Unix): pour chaque commande, vous pouvez taper man git-commande.
Sur les messages de commit : https://ensiwiki.ensimag.fr/index.php/%C3%89crire_de_bons_messages_de_commit_avec_Git
le guide complet en anglais sur l’utilisation de Git dans Eclipse