10. Lecture de données#
Une fois résolus les problèmes d’association entre le modèle objet et le schéma relationnel, nous pouvons nous intéresser à l’accès aux données. Nous en avons déjà eu un rapide aperçu dans les chapitres précédents, mais il est temps maintenant d’adopter une approche plus systématique, de comprendre quels sont les mécanismes à l’œuvre, et de s’interroger sur les performances d’un accès à une base de données via un ORM.
Pratique: contrôleur, modèle et vue
Pour les exercices et exemples de ce chapitre, je vous propose de créer
un nouveau contrôleur, nommé Requeteur, associé à l’URL
requeteur. Pour les différentes méthodes de lecture étudiées, créez
une classe Lectures.java qui tiendra lieu de modèle.
S1: Comment fonctionne Hibernate#
Supports complémentaires :
Nous avons défini le mapping ORM, sur lequel Hibernate s’appuie pour accéder aux données, en écriture et en lecture. Regardons maintenant comment sont gérés, en interne, ces accès. Pour l’instant nous allons nous contenter de considérer les lectures de données à partir d’une base existante, sans effectuer aucune mise à jour. Celà exclut donc la question des transactions qui, comme nous le verrons plus tard, est assez délicate. En revanche cela nous permet d’aborder sans trop de complication l’architecture d’Hibernate et le fonctionnement interne du mapping et de la matérialisation du graphe d’objet à partir de la base relationnelle.
Note
Le titre de ce chapitre utilise le terme lecture, et pas celui de requête plus habituel dans un contexte base de données. Cette distinction a pour but de souligner qu’une application ORM accède aux données (en lecture donc) par différents mécanismes, dont la navigation dans le graphe d’objet. Les requêtes effectuées sont souvent déterminées et exécutées par la couche ORM, sans directive explicite du programmeur. Gardez à l’esprit dans tout ce chapitre que notre application gère un graphe d’objet, pas une base de données tabulaires.
L’architecture#
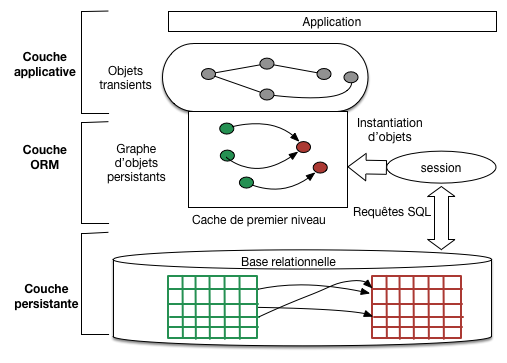
Figure 1: Les 3 couches d’une application ORM#
Regardons à nouveau la structuration en couches d’une application s’appuyant sur un framework ORM (Figure Les 3 couches d’une application ORM). L’application, écrite en Java, manipule des objets que nous pouvons séparer en deux catégories:
les objets transients sont des objets Java standard, instanciés par l’opérateur new, dont le cycle de vie est géré par le garbage collector;
les objets persistants sont également des objets java, instances d’une classe persistante (définie par l’annotation
@Entity) et images d’une ligne dans une table de la base relationnelle.
L’appartenance à une classe persistante est une condition nécessaire pour qu’un objet devienne persistant, mais ce n’est pas une condition suffisante. Il faut également que l’objet soit placé sous le contrôle du composant chargé de la persistance, soit, pour Hibernate, l’objet session. Pour le dire autrement, on peut très bien instancier un objet d’une classe persistante et l’utiliser dans un cadre de programmation normal (dans ce cas c’est un objet transient), sans le stocker dans la base.
Note
Il existe en fait une troisième catégorie, les objets détachés, que nous présenterons dans la chapitre Applications concurrentes.
Les objets persistants sont placés dans un espace nommé le cache de premier niveau dans Hibernate, que l’on peut simplement voir comme l’emplacement où se trouve matérialisé (partiellement) le graphe des objets utilisés par l’application. Cette matérialisation est donc contrôlée et surveillée par un objet session que nous avons déjà utilisé pour accéder aux données, mais qu’il est maintenant nécessaire d’examiner en détail car son rôle est essentiel.
La session et le cache de premier niveau#
La session Hibernate définit l’espace de communication entre l’application
et la base de données. Essentiellement, cet objet a pour responsabilité
de synchroniser la base de données et le graphe d’objet. Pour nous
en tenir aux lectures, cette synchronisation consiste à transmettre
des requêtes SELECT via JDBC, pour lire des lignes et instancier des
objets à partir des valeurs de ces lignes.
Revenons à la figure Les 3 couches d’une application ORM. Deux tables (associées) sont illustrées, une verte, une rouge. Des lignes de chaque table sont représentées, sous forme d’objet persistant (rouge ou vert), dans le cache de premier niveau associé à la session. L’instantiation de ces objets a été déclenchée par des demandes de lecture de l’application. Ces demandes passent toujours par la session, soit explicitement, comme quand une requête HQL est exécutée, soit implicitement, quand par exemple lors d’une navigation dans le graphe d’objet.
La session est donc un objet absolument essentiel. Pour les lectures en particulier, son rôle est étroitement associé au cache de premier niveau. Elle assure en particulier le respect de la propriété suivante.
Propriété: unicité des références d’objet
Dans le contexte d’une session, chaque ligne d’une table est représentée par au plus un objet persistant.
En d’autres termes, une application, quelle que soit la manière dont elle accède à une ligne d’une table (requête, parcours de collection, navigation), obtiendra toujours la référence au même objet.
Cette propriété d’unicité est très importante. Imaginons le cas contraire: je fais par exemple plusieurs accès à un même film, et j’obtiens deux objets Java distincts (au sens de l’égalité des références, testée par ==), A et B. Alors:
si je fais des modifications sur A et sur B, quelle est celle qui prend priorité au moment de la sauvegarde dans la base?
toute modification sur A ne serait pas immédiatement visible sur B, d’où des incohérence, sources de bugs très difficiles à comprendre.
Le cache est donc une sorte de copie de la base de données au plus près de l’application (dans la machine virtuelle java) et sous forme d’objets. Voici encore une autre manière d’exprimer les choses.
Corollaire: identité Java et identité BD
Dans le contexte d’une session, l’identité des objets est équivalente
à l’identité base de données. Deux objets sont identiques (== renvoie true)
si et seulement
si ils ont les mêmes clés primaires.
Le test:
a == b
est donc toujours équivalent à:
A.getId().equals(B.getId())
Concrètement, cela implique un fonctionnement assez contraint pour la session: à chaque accès à la base ramenant un objet, il faut vérifier, dans le cache de premier niveau, si la ligne correspondante n’a pas déjà été instanciée, et si oui renvoyer l’objet déjà présent dans le cache. Pour reprendre l’exemple précédent:
l’application fait une lecture (par exemple par une requête) sur la table Film, l’objet A correspondant à la ligne l est instancié, placé dans le cache de premier niveau, et sa référence est transmise à l’application;
l’application fait une seconde demande de lecture (par exemple en naviguant dans le graphe); cette lecture a pour paramètre la clé primaire de la ligne l: alors la session va d’abord chercher dans le cache de premier niveau si un objet correspondant à l existe; si oui sa référence est renvoyée, si non une requête est effectuée;
l’application ré-exécute une requête sur la table Film, et parcourt les objets avec un itérateur; alors à chaque itération il faut vérifier si la ligne obtenue est déjà instanciée dans le cache de premier niveau.
Vous devez être bien conscients de ce mécanisme pour comprendre comment fonctionne Hibernate, et le rôle combiné de la session et du cache de premier niveau.
Note
Notez bien la restriction « dans le contexte d’une session. ». Si vous fermez une session s1 pour en ouvrir une autre s2, tout en gardant la référence vers A, la propriété n’est plus valable car A ne sera pas dans le cache de premier niveau de s2. À plus forte raison, deux applications distinctes, ayant chacune leur session, ne partageront pas leur cache de premier niveau.
Le cache de premier niveau est structuré de manière à répondre très rapidement au test suivant: « Donne
moi l’objet dont la clé primaire est C ». La structure la plus efficace est une table
de hachage. La figure Une table de hachage du cache de premier niveau montre la structure. Une fonction H prend
en entrée une valeur de clé primaire k, l, m ou n (ainsi que le nom de la table T)
et produit une valeur de hachage comprise entre 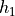 et
et 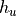 . Un répertoire associe à chacune
de ces valeurs de hachage une entrée comprenant un ou plusieurs objets java
. Un répertoire associe à chacune
de ces valeurs de hachage une entrée comprenant un ou plusieurs objets java 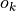 ,
,
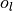 ,
, 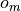 ou
ou 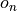 . Notez qu’il peut y avoir
des collisions: deux clés distinctes mènent à une même entrée, contenant les objets correspondants.
. Notez qu’il peut y avoir
des collisions: deux clés distinctes mènent à une même entrée, contenant les objets correspondants.
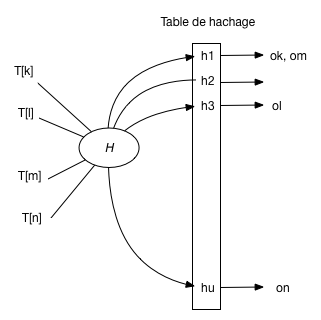
Figure 2: Une table de hachage du cache de premier niveau#
En résumé, pour tout accès à une ligne de la base, c’est toujours le même objet qui est retourné à l’application. Le cache de premier niveau conserve tous les objets persistants, et c’est dans ce cache que l’application (ou plutôt la session courante) vient piocher. Ce cache n’est pas partagé avec une autre application (ou plus précisément avec une autre session).
Note
Comme vous vous en doutez peut-être, il existe un cache de second niveau qui, lui a des propriétés différentes. Laissons-le de côté pour l’instant.
À propos de hashCode() et equals()#
Il est recommandé, dans certains cas, d’implanter les méthodes hashCode() et
equals() dans les classes d’objet persistants. La situation qui rend cette implantation nécessaire
est caractérisée comme suit.
Quand faut-il implanter hashCode() et equals()?
Si des instances d’une classe persistante doivent être conservées dans
une collection (Set, List ou Map) qui couvre plusieurs sessions
Hibernate, alors il est nécessaire de fournir une implantation spécifique de hashCode() et equals()
Disons-le tout de suite avant d’entrer dans les détails: il vaut mieux éviter cette situation, car elle soulève des problèmes qui n’ont pas de solution entièrement satisfaisante. À ce stade, vous pouvez donc décider que vous éviterez toujours de vous mettre dans ce mauvais cas, ce qui vous évite de plus d’avoir à lire ce qui suit. Sinon (ou si vous voulez vraiment comprendre de quoi il s’agit), continuez la lecture de cette section et faites-vous une idée par vous-mêmes de la fragilité introduite dans l’application par ce type de pratique.
Note
La discussion qui suit est relativement scabreuse et vous pouvez l’éviter, au moins en première lecture. Il n’est pas forcément indispensable de se charger l’esprit avec ces préoccupations.
Ce qui pose problème#
Voici, sous forme de code synthétisé, un exemple de situation problématique.
// On maintient une liste des utilisateurs
Set<User> utilisateurs;
// Ouverture d'une première session
Session s1 = sessionFactory.openSession();
// On ajoute l'utilisateur 1 à la liste
User u1 = s1.load (User.class, 1);
utilisateurs.add (u1);
// Fermeture de s1
s1.close();
// Idem, avec une session 2
Session s2 = sessionFactory.openSession();
User u2 = s2.load (User.class, 1);
utilisateurs.add (u2);
s2.close();
Ce code instancie deux objets persistants u1 et u2, correspondant à la même ligne,
mais qui ne sont pas identiques puisqu’ils
ont été chargés par deux sessions différentes. Ils sont insérés dans le Set utilisateurs,
et comme leur hashCode (qui repose par défaut sur l’identité des objets) est différent,
ce Set contient donc un doublon, ce qui ouvre la porte à toutes sortes de bugs.
Rappel sur le rôle de hashCode() et equals().
Vous pouvez vous reporter à la documentation.
Conclusion: il faut dans ce cas implanter hashCode() et equals() non pas sur l’identité objet,
mais en tenant compte de la valeur des objets pour détecter que ce sont les mêmes. Notez que le problème
ne se pose pas si on reste dans le cadre d’une seule session.
Solution#
Une solution immédiate, mais qui ne marche pas, est d’implanter l’égalité sur l’identifiant
en base de données (l’attribut id). Cela ne marche pas dans le cas des identifiants
auto-générés, car la valeur de ces identifiants n’est pas connue au moment où on les instancie.
Exemple:
utilisateurs.add (new User("philippe"));
utilisateurs.add (new User("raphaël"));
On crée deux instances, pour lesquellles (tant qu’on n’a pas faite de save()) l’identifiant
est à null. Si on base la méthode hashCode() sur l”id, seul le premier objet sera
placé dans le Set utilisateur.
La seule solution est donc de trouver un ou plusieurs attributs de l’objet persistant qui forment une clé dite « naturelle », à savoir:
identifiant l’objet de manière unique,
dont la valeur est toujours connue,
et qui ne change jamais.
C’est ici que l’on peut affirmer qu’il n’existe à peu près jamais un cas où ces critères sont satisfaits à 100%. Il restera donc toujours un doute sur la robustesse de l’application.
Ces réserves effectuées, voici un exemple d’implantation de ces deux méthodes, en supposant que le nom de l’utilisateur est une clé naturelle (ce qui est faux bien sûr).
@Override
public int hashCode() {
HashCodeBuilder hcb = new HashCodeBuilder();
hcb.append(nom);
return hcb.toHashCode();
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (!(obj instanceof User)) {
return false;
}
User autre = (User) obj;
EqualsBuilder eb = new EqualsBuilder();
eb.append(nom, autre.nom);
return eb.isEquals();
}
Conclusion:
Je vous déconseille tout à fait d’ouvrir et fermer des sessions, à moins d’avoir une excellente raison et de comprendre l’impact, illustré par l’exercice précédent.
Je vous déconseille également de stocker dans des structures annexes des objets persistants: la base de données est là pour ça.
Note
Pour votre culture, un objet qui a été persistant et est soustrait du cache (par exemple parce que la session est fermée est un objet détaché. C’est un troisième statut, après transient et persistant.
Exercice: vérifier l’unicité, dans le contexte d’une session
Ecrivez une action qui lit deux fois le même film dans deux objets a et b, et vérifiez que ces deux objets sont identiques.
Complétez le test en utilisant deux sessions successives, en fermant la première et en en ouvrant une seconde. Lisez le même film dans un objet c et vérifiez qu’il n’est pas identique aux précédents.
Si votre application conserve des références à a, b, et c, vous obtenez donc (en ouvrant/fermant des sessions) des objets distincts correspondant à la même ligne.
NB: la lecture d’une ligne avec la clé primaire s’effectue avec:
session.load(Film.class, idFilm)
Exercice: comprendre le rôle de hashCode() et equals()
Pour chaque fragment de code ci-dessous, indiquez si l’assertion est un succès ou un échec, dans les cas suivants:
hashCode()etequals()par défaut;
hashCode()etequals()basés sur la clé relationnelle (id);
hashCode()etequals()basés sur une clé métier.
Justifiez votre réponse (et testez vous-mêmes pour vérifier).
HashSet someSet = new HashSet();
someSet.add(new PersistentClass());
someSet.add(new PersistentClass());
assert(someSet.size() == 2);
PersistentClass p1 = sessionOne.load(PersistentClass.class, new Integer(1));
PersistentClass p2 = sessionTwo.load(PersistentClass.class, new Integer(1));
assert(p1.equals(p2));
HashSet set = new HashSet();
User u = new User();
set.add(u);
session.save(u);
assert(set.contains(u));
S2: Les opérations de lecture#
Supports complémentaires :
Maintenant que vous comprenez le fonctionnement interne d’Hibernate, au moins pour les grands principes, nous allons regarder rapidement les différentes options de lecture de données. Voici la liste des possibilités:
par navigation dans le graphe des objets, si nécessaire chargé à la volée par Hibernate;
par identifiant: méthode basique, rapide, et de fait utilisée implicitement par d’autres méthodes comme la navigation;
par le langage de requêtes HQL;
par l’API
Criteria, qui permet de construire par programmation objet une requête à exécuter;enfin, directement par SQL, ce qui n’est pas une méthode portable et devrait donc être évité.
Nous passons ces méthodes en revue dans ce qui suit.
Accès par la clé#
Deux méthodes permettent d’obtenir un objet par la valeur de sa clé. La
première est get, dont voici une illustration:
return (Film) session.get(Film.class, id);
La seconde est load dont l’appel est strictement identique:
return (Film) session.load(Film.class, id);
Dans les deux cas, Hibernate examine d’abord le cache de la session pour trouver l’objet, et transmet une requête à la base si ce dernier n’est pas dans le cache. Les différences entre ces deux méthodes sont assez simples.
si
load()ne trouve par un objet, ni dans le cache, ni dans la base, une exception est levée;get()ne lève jamais d’exception;la méthode
load()renvoie parfois un proxy à la place d’une instance réelle.
Notion: que’est-ce qu’un proxy
Un proxy, en général, est un intermédiaire entre deux composants d’une application. Dans notre cas, un proxy est un objet non persistant, qui joue le rôle de ce dernier, et se tient prêt à accéder à la base si vraiment des informations complémentaires sont nécessaires.
Retenez qu’un proxy peut décaler dans le temps l’accès réel à la base, et donc la découverte
que l’objet n’existe pas en réalité. Il semble préférable d’utiliser systématiquement get(),
quitte à tester un retour avec la valeur null.
Exercice: accès direct par la clé
Ecrivez une action lectureParCle() qui appelle get() et load(), d’abord pour un identifiant
de film qui existe (par exemple, 1), puis pour un qui n’existe pas (par exemple, -1).
Dans le second cas, gérez la non-existence par un test approprié pour chaque méthode.
Le langage HQL#
Bien entendu l’accès à une ligne/objet par son identifiant trouve rapidement ses limites, et il est indispensable de pouvoir également exprimer des requêtes complexes. HQL (pour Hibernate Query Language bien sûr) est un langage de requêtes objet qui sert à interroger le graphe (virtuel au départ) des objets java constituant la vue orientée-objet de la base. Autrement dit, on interroge un ensemble d’objets java liés par des associations, et pas directement la base relationnelle qui permet de les matérialiser. Hibernate se charge d’effectuer les requêtes SQL pour matérialiser la partie du graphe qui satisfait la requête.
Voici un exemple simple de recherche de films par titre avec HQL.
public List<Film> parTitre(String titre)
{
Query q = session.createQuery("from Film f where f.titre= :titre");
q.setString ("titre", titre);
return q.list();
}
Remarquez que la clause select est optionnelle en HQL: on interroge des
objets, et la projection sur certains attributs offre peu d’intérêt. Elle a également
le grave inconvénient de produire une structure (un ensemble de listes de valeurs) qui
n’est pas pré-existante dans l’application, contrairement au modèle objet mappé sur la base.
Sans la clause select, on obtient directement une collection des objets du graphe, sans
acun travail de décryptage complémentaire.
Seconde remarque: comme en jdbc, on peut coder dans la requête des paramètres (ici, le titre) en les préfixant par « : » (« ? » est également accepté). Hibernate se charge de protéger la syntaxe de la requête, par exemple en ajoutant des barres obliques devant les apostrophes et autres caractères réservés.
Important
Il est totalement déconseillé de construire une requête comme une chaîne de caractères, à grand renfort de concaténation pour y introduire des paramètres.
Insistons sur le fait que HQL est un langage objet, même s’il ressemble beaucoup
à SQL. Il permet de naviguer dans le graphe par exemple avec la clause where. Voici
un exemple.
from Film f
where f.realisateur.nom='Eastwood'
L’API Criteria#
Hibernate propose un ensemble de classes et de méthodes pour construire des requêtes sans avoir à respecter une syntaxe spécifique très différente de java.
public List<Film> parTitreCriteria(String titre)
{
Criteria criteria = session.createCriteria(Film.class);
criteria.add (Expression.eqOrIsNull("titre", titre));
return criteria.list();
}
On ajoute donc (par exemple) des expressions pour indiquer les restrictions
de la recherche. Il n’y a aucune possibilité de commettre une erreur syntaxique, et
une requête construite avec Criteria peut donc être vérifiée à la complilation.
C’est, avec le respect d’une approche tout-objet, l’argument principal pour cette API
au lieu de HQL. Cela dit, on peut aussi estimer qu’une requête HQL est plus concise et
plus lisible. Le débat est ouvert et chacun juge selon ses goûts et ses points forts
(êtes-vous plus à l’aise en programmation objet ou en requêtage SQL?).
Nous avons choisi dans ce qui suit de présenter uniquement HQL, et d’ignorer
l’API Criteria que nous vous laissons explorer par vous-mêmes si vous pensez qu’il s’agit d’une
approche plus propre.
Exercice: un premier formulaire de recherche
Vous en savez assez pour créer une première fonction de recherche de films combinant quelques
critères comme: le titre, l’année (ou un intervalle d’année), le genre.
Proposez un formulaire HTML pour saisir ces critères, exécutez la requête en HQL et/ou
avec l’API Criteria, affichez le résultat.
Résumé: savoir et retenir#
L’information essentielle à retenir de ce chapitre est le rôle joué par la session Hibernate et le cache des objets maintenu par cette session. Il doit être clair pour vous qu’Hibernate consacre beaucoup d’efforts à maintenir dans le cache une image objet cohérente et non redondante de la base. Cela impacte l’exécution de toutes les méthodes d’accès dont nous avons donné un bref aperçu.
Manipulez l’objet Session avec précaution. Une méthode saine (dans le contexte d’une
application Web) est d’ouvrir une session en début d’action, et de la fermer à la fin.