8. JPA: le mapping#
Nous abordons maintenant une étude plus systématique de JPA/Hibernate en commençant par la définition du modèle de données, ou plus exactement de l’association (mapping) entre la base de données relationnelle et le modèle objet java. Nous parlerons plus concisément de mapping O/R dans ce qui suit. Rappelons le but de cette spécification: transformer automatiquement une base relationnelle en graphe d’objets java. Cette transformation est effectuée par Hibernate sur des données extraites de la base avec des requêtes SQL.
Note
nous considérons pour l’instant que la base est pré-existante, comme notre base webscope. Une autre possibilité, plus radicale, est de définir un modèle objet et de laisser Hibernate générer le schéma relationnel correspondant.
Le but de ce chapitre est principalement de finaliser notre modèle java pour la base webscope, ce qui couvrira les options les plus courantes du mapping O/R. Il existe plusieurs méthodes pour définir un modèle O/R.
par un fichier de configuration XML;
par des annotations directement intégrées au code java.
L’option « annotation » présente de nombreux avantages, pour la clarté, les manipulations de fichier, la concision. C’est donc celle qui est présentée ci-dessous. Reportez-vous à la documentation Hibernate si vous voulez inspectez un fichier de configuration XML typique.
Prudence
Attention, quand vous regardez les (innombrables) documentations sur le Web, à la date de publication; les outils évoluent rapidement, et beaucoup de tutoriaux sont obsolètes.
Pour utiliser les annotations JPA, il faut inclure le package javax.persistence.*.
Il nous semble préférable de suivre JPA le plus possible plutôt que la syntaxe
spécifique à Hibernate, la tendance de toute façon étant à la convergence de ce dernier vers la norme.
S1: Entités et composants#
Supports complémentaires :
Une entité, déclarée par l’annotation @Entity définit une classe Java comme étant
persistante et donc associée à une table dans la base de données. Cette classe
doit être implantée selon les normes des beans: propriétés déclarées
comme n’étant pas publiques (private est sans doute le bon choix), et accesseurs avec set
et get, nommés selon les conventions habituelles.
Par défaut, une entité est associée à la table portant le même nom que la classe. Il est
possible d’indiquer le nom de la table par une annotation @Table. En voici un exemple (parfaitement
inutile en l’occurrence):
@Entity
@Table(name="Film")
public class Film {
...
}
De nombreuses options JPA, et plus encore Hibernate, sont disponibles, mais nous allons nous limiter à l’essentiel pour comprendre les mécanismes. Vous pourrez toujours vous reporter à la documentation pour des besoins ponctuels.
La norme JPA indique qu’il est nécessaire de créer un constructeur vide pour chaque
entité. Le framework peut en effet avoir à instancier une entité avec un appel
à Constructor.newInstance() et le constructeur correspondant doit exister. La norme
JPA indique que ce constructeur doit être public ou protégé:
public Film() {}
La méthode ci-dessus a l’inconvénient de créer un objet dans un état invalide (aucune
propriété n’a de valeur). Cela ne pose pas de problème quand c’est Hibernate qui
utilise ce constructeur puisqu’il va affecter les propriétés en fonction des valeurs
dans la base, mais du point de vue de l’application c’est une source potentielle d’ennuis. Avec
Hibernate, le constructeur vide peut être déclaré private (mais ce n’est pas
la recommandation JPA).
Finalement, il est recommandé, au moins pour certaines classes, d’implanter des méthodes equals() et hashCode() pour qu’Hibernate puisse déterminer si deux objets correspondent à la même ligne de la base. C’est un sujet un peu trop avancé pour l’instant, et nous le laissons donc de côté.
Important
Nous nous soucions essentiellement pour l’instant d’opération de lecture, qui suffisent à illustrer et valider la modélisation du mapping.
Identifiant d’une entité#
Toute entité doit avoir une propriété déclarée comme étant l’identifiant de la ligne dans la table correspondante. Il est beaucoup plus facile de gérer une clé constituée d’une seule valeur qu’une clé composée de plusieurs. Les bases de données conçues selon des principes de clé artificielle ou surrogate key (produite à partir d’une séquence) sont de loin la meilleure solution. On peut être confronté à une base qui n’a pas été conçue sur ce principe, auquel cas JPA/Hibernate fournit des méthodes permettant de faire face à la situation, mais c’est plus compliqué. Nous présentons une solution à la fin de ce chapitre.
L’identifiant est indiqué avec l’annotation @Id. Pour produire
automatiquement les valeurs d’identifiant,
on ajoute une annotation @GeneratedValue avec un paramètre Strategy. Voici
deux possibilités pour ce paramètre:
Strategy = GenerationType.AUTO. Hibernate produit lui-même la valeur des identifiants grâce à une tablehibernate_sequence.
Strategy = GenerationType.IDENTITY. Hibernate s’appuie alors sur le mécanisme propre au SGBD pour la production de l’identifiant. Dans le cas de MySQL, c’est l’optionAUTO-INCREMENT, dans le cas de postgres ou Oracle, c’est une séquence. C’est à vous de vous assurer que pour chaque table, ce mécanisme est en place.
Voici les commandes pour Film ou Artiste en utilisant le mécanisme automatique
d’Hibernate, en supposant que les clés primaires ne sont pas auto-incrémentées.
@Id
@GeneratedValue(Strategy = GenerationType.AUTO)
private Integer id;
private void setId(Integer i) { id = i; }
public Integer getId() { return id; }
Note
en stratégie GenerationType.AUTO, Hibernate doit se charger
de créer une table hibernate_sequence.
Si la clé est auto-incrémentée dans MySQL, l’annotation est la suivante.
@Id
@GeneratedValue(Strategy = GenerationType.IDENTITY)
private Integer id;
Faut-il fournir des accesseurs setId() et getId()? Conceptuellement, l’id est utilisé pour
lier un objet à la base de données et ne joue aucun rôle dans l’application. Il n’a donc pas de raison d’apparaître publiquement.
d’où l’absence de méthode pour le récupérer dans la plupart des objets métiers.
fournir une méthode publique
setId()pour un identifiant auto-généré ne semble pas une bonne idée, car dans ce cas l’application pourrait affecter un identifiant en conflit avec la méthode de génération; il est donc préférable de créer une méthode privée;fournir une méthode
getId()n’est pas nécessaire, sauf si l’application souhaite inspecter la valeur de l’identifiant en base de données, ce qui est de fait souvent utile.
En résumé, la méthode setId()``devrait être ``private. Notez qu’Hibernate utilise l’API
Reflection de java pour acéder aux propriétés des objets, et n’a donc pas besoin
de méthodes publiques.
Note
Avec Hibernate, l’existence de setId() ne semble même pas nécessaire. Il semble que
JPA requiert des accesseurs pour chaque propriété mappée, donc autant respecter cette règle
pour un maximum de compatibilité.
Les colonnes#
Par défaut, toutes les propriétés non-statiques d’une classe-entité sont considérées
comme devant être stockées dans la base. Pour indiquer des options (et aussi
pour des raisons de clarté à la lecture du code) on utilise le plus souvent
l’annotation @Column, comme par exemple:
@Column
private String nom;
public void setNom(String n) {nom= n;}
public String getNom() {return nom;}
Cette annotation est utile pour indiquer le nom de la colonne dans
la table, quand cette dernière est différente du nom de la propriété en java. Dans
notre cas nous utilisons des règles de nommage différentes en java et dans la
base de données pour les noms composés de plusieurs mots. @Column permet
alors d’établir la correspondance:
@Column(name="annee_naissance")
private Integer anneeNaissance;
public void setAnneeNaissance(Integer a) {anneeNaissance = a;}
public Integer getAnneeNaissance() {return anneeNaissance;}
Voici les principaux attributs pour @Column.
nameindique le nom de la colonne dans la table;
lengthindique la taille maximale de la valeur de la propriété;
nullable(avec les valeursfalseoutrue) indique si la colonne accepte ou non des valeurs àNULL(au sens « base de données » du terme: une valeur àNULLest une absence de valeur);
uniqueindique que la valeur de la colonne est unique.
Note
Un objet métier peut très bien avoir des propriétés que l’on ne souhaite pas rendre persistantes
dans la base. Il faut alors impérativement les marquer avec l’annotation @Transient.
Les composants#
Une entité existe par elle-même indépendamment de toute autre entité, et peut être rendue persistante par insertion dans la base de données, avec un identifiant propre. Un composant, au contraire, est un objet sans identifiant, qui ne peut être persistant que par rattachement (direct ou transitif) à une entité.
La notion de composant résulte du constat qu’une ligne dans une base de données peut parfois être décomposée en plusieurs sous-ensemble dotés chacun d’une logique autonome. Cette décomposition mène à une granularité fine de la représentation objet, dans laquelle on associe plusieurs objets à une ligne de la table.
On peut sans doute modéliser une application sans recourir aux composants, au moins dans la définition stricte ci-dessus. Ils sont cependant également utilisés dans Hibernate pour gérer d’autres situations, et notamment les clés composées de plusieurs attributs, comme nous le verrons plus loin. Regardons donc un exemple concret, celui (beaucoup utilisé) de la représentation des adresses. Prenons donc nos internautes, et ajoutons à la table quelques champs (au minimum) pour représenter leur adresse.
ALTER TABLE Internaute ADD adresse TEXT,
ADD code_postal VARCHAR(10), ADD ville VARCHAR(100);
Utilisez phpMyAdmin pour insérer quelques adresses aux internautes existant dans la base, et passons maintenant à la modélisation java.
On va considérer ici que l’adresse est un composant de la représentation
d’un internaute qui dispose d’une unité propre et distinguable du reste
de la table. Cela peut se justifier, par exemple, par la nécessité de
contrôler qu’un code postal est correct, une logique applicative
qui n’est pas vraiment pertinente pour l’entité Internaute. Un autre argument
est qu’on peut réutiliser la définition du composant pour
d’autres entités, comme par exemple Société.
Toujours
est-il que nous décidons de représenter une adresse comme un composant,
désigné par le mot-clé Embeddable en JPA.
package modeles.webscope;
import javax.persistence.*;
@Embeddable
public class Adresse {
String adresse;
public void setAdresse(String v) {adresse = v;}
public String getAdresse() {return adresse;}
@Column(name="code_postal")
String codePostal;
public void setCodePostal(String v) {codePostal = v;}
public String getCodePostal() {return codePostal;}
String ville;
public void setVille(String v) {ville = v;}
public String getVille() {return ville;}
}
La principale différence visible avec une entité est qu’un composant n’a
pas d’identifiant (marqué @Id) et ne peut donc pas être sauvegardé
dans la base indépendamment. Il faut au préalable le rattacher à une entité, ici
Internaute.
package modeles.webscope;
import javax.persistence.*;
@Entity
public class Internaute {
@Id
private String email;
public void setEmail(String e) {email = e;}
@Column
private String nom;
public void setNom(String n) {nom = n;}
public String getNom() {return nom;}
@Column
private String prenom;
public void setPrenom(String p) {prenom = p;}
public String getPrenom() { return prenom;}
@Embedded
private Adresse adresse;
public void setAdresse(Adresse a) {adresse = a;}
public Adresse getAdresse() {return adresse;}
}
Au lieu de l’annotation Column, on utilise @Embedded et le tour est joué.
La propriété adresse devient, comme nom et prénom, une propriété
persistante de l’entité.
Exercice: affichez la liste des internautes.
Implantez une action qui affiche la liste des internautes avec leur adresse.
Vous remarquerez que la classe Adresse contient des annotations qui le mappent vers
la table, notamment avec les noms de colonne. Mais que se passe-t-il alors si
on place deux composants du même type dans une entité? Par exemple, si on
veut avoir une adresse personnelle et une adresse professionnelle pour un internaute?
On mapperait dans ce cas deux propriétés distinctes vers la même colonne.
Pour illustrer le problème (et la solution), commençons par modifier la table.
ALTER TABLE Internaute ADD adresse_pro TEXT,
ADD code_postal_pro VARCHAR(10), ADD ville_pro VARCHAR(100);
On indique alors, dans le composé (l’entité), le mapping entre
la table de l’entité et le nouveau composant, autrement dit les colonnes
de la table qui doivent stocker les propriétés du composant. C’est une surcharge
(override en anglais), d’où la syntaxe suivante en JPA, à ajouter à la classe
Internaute.
@Embedded
@AttributeOverrides( {
@AttributeOverride(name="adresse", column = @Column(name="adresse_pro") ),
@AttributeOverride(name="codePostal", column = @Column(name="code_postal_pro") ),
@AttributeOverride(name="ville", column = @Column(name="ville_pro") )
}
)
private Adresse adressePro;
public void setAdressePro(Adresse a) {adressePro = a;}
public Adresse getAdressePro() {return adressePro;}
L’attribut codePostal du composant adressePro sera donc par exemple stocké
dans la colonne code_postal_pro.
Exercice: affichez les adresses personnelle et professionelle.
Etendez l’action précédente pour affichez les deux adresses. Au préalable, utilisez phpMyAdmin pour saisir quelques valeurs d’adresse professionnelle.
Exercice: mappez toutes les entités de la base webscope
Définissez une classe pour chaque entité de la base webscope, avec un mapping utlisant les annotations vues jusqu’à présent. Attention: nous parlons bien des entités (cf. le modèle UML) et pas des associations qui parfois, sont aussi représentées par des tables.
S2: associations un-à-plusieurs#
Supports complémentaires :
Venons-en maintenant aux associations. Nous laissons de côté les associations « un à un » qui sont peu fréquentes et nous en venons directement aux associations « un à plusieurs ». Notre exemple prototypique dans notre base de données est la relation entre un film et son (unique) réalisateur. Un premier constat, très important: en java nous pouvons représenter l’association de trois manières, illustrées sur la figure Trois possibilités pour une association un à plusieurs.
dans un film, on place un lien vers le réalisateur (unidirectionnel, à gauche);
dans un artiste, on place des liens vers les films qu’il a réalisés (unidirectionnel, centre);
on représente les liens des deux côtés (bidirectionnel, droite).
Rappelons que dans une base relationnelle, le problème ne se pose pas: une association représentée par une clé étrangère est par nature bidirectionnelle. Cette différence est due aux deux paradigmes opposés sur lesquels s’appuient le modèle relationnel d’une part (qui considère des ensembles sans liens explicites entre eux, une association étant reconstitué par un calcul de jointure) et le modèle objet de java (qui établit une navigation dans les objets instantiés grâce aux références d’objets).
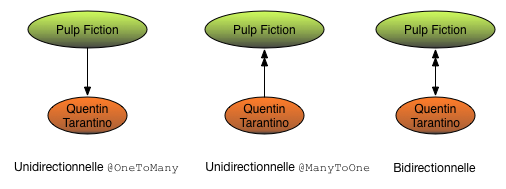
Figure 1: Trois possibilités pour une association un à plusieurs#
Ceci étant posé, voyons comment nous pouvons représenter les trois situations, pour un même état de la base de données.
L’annotation @ManyToOne#
Nous avons déjà étudié ce cas de figure. Dans la classe Film, nous indiquons
qu’un objet lié nommé réalisateur, de la classe Artiste, doit être cherché dans
la base par Hibernate.
@ManyToOne
@JoinColumn (name="id_realisateur")
private Artiste realisateur;
public void setRealisateur(Artiste a) {realisateur = a;}
public Artiste getRealisateur() {return realisateur;}
L’annotation @JoinColumn indique quelle est la clé étrangère dans Film qui permet de rechercher
l’artiste concerné. En d’autres termes, quand on appelle getRealisateur(), Hibernate doit
engendrer et exécuter la requête suivante;
select * from Artiste where id = ?film.id_realisateur
où ?film désigne l’objet-film courant.
Important
Vous pouvez noter qu’avec le comportement simpliste décrit ci-dessus, on effectue une requête SQL pour rechercher un objet, ce qui constitue une utilisation totalement sous-optimale de SQL et risque d’engendrer de très gros problèmes de performance pour des bases importantes. Gardez cette remarque sous le coude, nous y reviendrons plus tard.
Hibernate sait bien entendu représenter l’association (clé primaire / clé étrangère) dans la base,
en transposant la référence objet d’un artiste par un film. Voici concrètement comment cela se passe.
Créons l’action insertFilm ci-dessous.
public void insertFilm() {
session.beginTransaction();
Film gravity = new Film();
gravity.setTitre("Gravity");
gravity.setAnnee(2013);
Genre genre = new Genre();
genre.setCode("Science-fiction");
gravity.setGenre(genre);
Artiste cuaron = new Artiste();
cuaron.setPrenom("Alfonso");
cuaron.setNom("Cuaron");
// Le réalisateur de Gravity est Alfonso Cuaron
gravity.setRealisateur(cuaron);
// Sauvegardons dans la base
session.save(gravity);
session.save(cuaron);
session.getTransaction().commit();
}
On a donc créé le film Gravity, de genre Science-Fiction et mis en scène par Alfonso Cuaron. L’association est créée, au niveau du graphe d’objets java par l’instruction:
gravity.setRealisateur(cuaron);
On a ensuite sauvegardé les deux nouvelles entités dans la base. Exécutons cette action, et regardons ce qui s’affiche dans la console:
Hibernate: select genre_.code from Genre genre_ where genre_.code=?
Hibernate: insert into Film (annee, genre, code_pays,
d_realisateur, resume, titre) values (?, ?, ?, ?, ?, ?)
Hibernate: insert into Artiste (annee_naissance, nom, prenom) values (?, ?, ?)
Hibernate: update Film set annee=?, genre=?, code_pays=?, id_realisateur=?,
resume=?, titre=? where id=?
Ce que l’on voit: Hibernate a engendré et exécuté des requêtes SQL. La première sélectionne
le genre Science-Fiction: comme nous avons indiqué la valeur de la clé primaire dans
l’instance Java, Hibernate vérifie automatiquement si cet objet Genre existe dans la base
et va le lire si c’est le cas opur le lier par référence à l’objet
Film en cours de création. Hibernate cherche toujours à synchroniser le graphe
des objets et la base de données quand c’est nécessaire.
Le premier insert est déclenché par l’instruction session.save(gravity). Il
insère le film. À ce stade l’identifiant du metteur en scène dans la
base est à NULL puisque Cuaron n’a pas encore été sauvegardé. Nous pouvons
donc, à un moment donné, associer un objet persistant (le film ici)
à un objet transient (l’artiste).
Le second insert correspond à session.save(cuaron).
Il insère l’artiste, qui obtient alors un identifiant dans la base de données.
Et du coup Hibernate effectue un update sur le film pour affecter cet identifiant
à la colonne id_realisateur.
Note
On remarque que tous les champs de Film sont modifiés par l”update
alors que seul l’identifiant du metteur en scène a changé. Hibernate ne gère pas
les modifications au niveau des attributs mais se contente - c’est déjà beaucoup -
de détecter toute modification de l’objet java pour déclencher une synchronisation
avec la base. Nous reviendrons sur tout cela quand nous parlerons des transactions.
En résumé, tout va bien. Pour un effort minime nous obtenons une gestion complète de l’association entre un film et son metteur en scène. Hibernate synchronise les actions effectuées sur le graphe des objets persistants en java avec la base de données, que ce soit en lecture ou en écriture.
C’est aussi le bon endroit pour noter concrètement la différence, en ce qui concerne les associations, entre la représentation relationnelle et le modèle de données en java. Il n’est pour l’instant pas possible de récupérer la liste des films réalisés par Alfonson Cuaron car nous n’avons pas représenté dans le modèle objet (Java) ce côté de l’association. En revanche, une simple jointure en SQL nous donnerait cette information.
L’annotation @OneToMany#
De l’autre côté de l’association, on utilise l’annotation @OneToMany: à un objet
correspondent plusieurs objets associés. Dans notre exemple, à un artiste correspondent
de 0 à plusieurs films réalisés.
Important
Mettez en commentaires, pour l’instant, la clause @ManyToOne
définissant le réalisateur
dans la classe Film, puisque nous étudions les associations unidirectionnelles:
/* @ManyToOne
@JoinColumn (name="id_realisateur")
private Artiste realisateur;
public void setRealisateur(Artiste a) {realisateur = a;}
public Artiste getRealisateur() {return realisateur;}
*/
Nous allons voir dans la prochaine session ce qui se passe quand on combine les deux.
Spécifions l’association @OneToMany dans
la classe Artiste.
@OneToMany
@JoinColumn(name="id_realisateur")
private Set<Film> filmsRealises = new HashSet<Film>();
public void addFilmsRealise(Film f) {filmsRealises.add(f) ;}
public Set<Film> getFilmsRealises() {return filmsRealises;}
Il n’y a pratiquement pas de différence avec la représentation @ManyToOne. On indique,
comme précédemment, que la clé étrangère est id_realisateur et Hibernate comprend
qu’il s’agit d’un attribut de Film, ce qui lui permet d’engendrer la même
requête SQL que précédemment.
L’association est représentée par une collection, ici un Set (notez
qu’on l’initialise avec un ensemble vide). On fournit
deux méthodes, add (au lieu de set pour le côté @ManyToOne) et get.
Tentons à nouveau l’insertion d’un nouveau
film et de son metteur en scène. Il suffit d’exécuter la même
méthode insertFilm que précédemment, en
remplaçant la ligne:
gravity.setRealisateur(cuaron);
par la ligne:
cuaron.addFilmsRealise(gravity);
Supprimez éventuellement les données insérées précédemment, dans phpMyAdmin, avec:
DELETE FROM Film where titre='Gravity';
DELETE FROM Artiste WHERE nom='Cuaron'
et exécutez cette action. Hibernate devrait afficher les requêtes suivantes dans la console:
Hibernate: select genre_.code from Genre genre_ where genre_.code=?
Hibernate: insert into Film (annee, genre, code_pays, id_realisateur,
resume, titre) values (?, ?, ?, ?, ?, ?)
Hibernate: insert into Artiste (annee_naissance, nom, prenom) values (?, ?, ?)
Hibernate: update Film set id_realisateur=? where id=?
Hibernate a effectué les insertions et les mises à jour
identiques à celles déjà vues pour l’association @ManyToOne. Là aussi, c’est normal
puisque nous avons changé l’association en java, mais au niveau de la base
elle reste représentée de la même manière.
Cette fois il n’est plus possible de connaître le metteur en scène d’un film puisque nous avons supprimé un des côtés de l’association. Il va vraiment falloir représenter une association bidirectionnelle. C’est ce que nous étudions dans la prochaine session. Faites au préalable l’exercice ci-dessous.
Exercice: afficher la liste des artistes avec les films qu’ils ont réalisés
Ecrire une action qui affiche tous les artistes et la liste des films qu’ils ont réalisés, quand c’est le cas. Aide: on devrait donc trouver deux boucles imbriquées dans la JSTL, une sur les artistes, l’autre sur les films.
S3: Associations bidirectionnelles#
Supports complémentaires :
Maintenant, que se passe-t-il si on veut représenter l’association
de manière bi-directionnelle, ce qui sera souhaité dans une bonne partie
des cas. C’est tout à fait pertinent par exemple pour notre exemple,
puisqu’on peut très bien vouloir naviguer dans l’association réalise
à partir d’un metteur en scène ou d’un film.
On peut tout à fait représenter l’association des deux côtés, en
plaçant donc simultanément dans la classe Film la spécification:
@ManyToOne
@JoinColumn (name="id_realisateur")
private Artiste realisateur;
public void setRealisateur(Artiste a) {realisateur = a;}
public Artiste getRealisateur() {return realisateur;}
et dans la classe Artiste la spécification:
@OneToMany
@JoinColumn(name="id_realisateur")
private Set<Film> filmsRealises = new HashSet<Film>();
public void addFilmsRealise(Film f) {filmsRealises.add(f) ;}
public Set<Film> getFilmsRealises() {return filmsRealises;}
Cette fois l’association est représentée des deux côtés.
Le problème#
Cela soulève cependant un problème
dû au fait que là où il y a deux emplacements distincts en java,
il n’y en a qu’un en relationnel. Effectuons
une dernière modification de insertFilm()
en affectant les deux côtés de l’assocation.
// Le réalisateur de Gravity est Alfonso Cuaron
gravity.setRealisateur(cuaron);
// Films réalisés par A. Curaon?
for (Film f : cuaron.getFilmsRealises()) {
System.out.println("Curaron a réalisé " + f.getTitre());
}
// Alfonso Cuaron a réalisé Gravity
cuaron.addFilmsRealise(gravity);
Au passage, on a aussi affiché la liste des films réalisés par Alfonso
Caron. Première remarque: le code est alourdi par la nécessité
d’appeler setRealisateur() et addFilmRealises() pour
attacher les deux bouts de l’association aux objets correspondants.
Exécutez à nouveau insertFilm()
(après avoir supprimé à nouveau de la base l’artiste et le film)
et regardons ce qui se passe. Hibernate affiche:
Hibernate: select genre_.code from Genre genre_ where genre_.code=?
Hibernate: insert into Film (annee, genre, code_pays,
id_realisateur, resume, titre) values (?, ?, ?, ?, ?, ?)
Hibernate: insert into Artiste (annee_naissance, nom, prenom) values (?, ?, ?)
Hibernate: update Film set annee=?, genre=?, code_pays=?,
id_realisateur=?, resume=?, titre=? where id=?
Hibernate: update Film set id_realisateur=? where id=?
Avez-vous d’abord noté ce que l’on ne voit pas? Normalement notre code devrait afficher
la liste des films réalisés par Alfonso Cuaron. Rien ne s’affiche, car nous avons
demandé cet affichage après avoir dit que Cuaron est le réalisateur de Gravity,
mais avant d’avoir dit que Gravity fait partie des films réalisés par
Cuaron. En d’autres termes, java ne sait pas, quand on renseigne un côté
de l’association, déduire l’autre côté. Cela semble logique quand on
y réfléchit, mais ça va mieux en le disant et en le constatant. Il
faut donc bien appeler setRealisateur() et addFilmRealises()
pour que notre graphe d’objets java soit cohérent. Si on ne le fait,
l’incohérence du graphe est potentiellement une source d’erreur pour l’application.
Seconde remarque: Hibernate effectue deux update, alors qu’un seul suffirait.
Là encore, c’est parce que les deux spécifications de chaque bout de l’association
sont indépendantes l’une de l’autre.
Ouf. Prenez le temps de bien réfléchir, car nous sommes en train d’analyser une des principales difficultés conceptuelles du mapping objet-relationnel.
(réflexion intense de votre part)
Le remède#
Bien, pour résumer nous avons deux objets java qui sont déclarés comme persistants (le fim, l’artiste). Hibernate surveille ces objets et déclenche une mise à jour dans la base dès que leur état est modifié. Comme la réalisation d’une association implique la modification des deux objets, alors que la base relationnelle représente l’association en un seul endroit (la clé étrangère), on obtient des mises à jour redondantes.
Est-ce vraiment grave? A priori on pourrait vivre avec, le principal
inconvénient prévisible étant un surplus de requêtes transmises à la
base, ce qui peut éventuellement pénaliser les performances. Ce n’est
pas non plus très satisfaisant, et Hibernate propose une
solution: déclarer qu’un côté de l’association est
responsable de la mise à jour. Cela se fait avec l’attribut
mappedBy, comme suit.
@OneToMany(mappedBy="realisateur")
private Set<Film> filmsRealises = new HashSet<Film>();
On indique donc que le mapping de l’association est pris en charge par
la classe Film, et on supprime l’annotation @JoinColumn puisqu’elle
devient inutile. Ce que dit mappedBy en l’occurrence, c’est qu’un
objet associé de la classe Film maintient un lien avec une instance
de la classe courante (un Artiste) grâce à une propriété nommée realisateur.
Hibernate, en allant inspecter la classe Film, trouvera que
realisateur est mappé avec la base de données par le biais de
la clé étrangère id_realisateur. Dans Film, on trouve en effet:
@ManyToOne
@JoinColumn (name="id_realisateur")
private Artiste realisateur;
Toutes les informations nécessaires sont donc disponibles, et représentées une seule fois. Cela semble compliqué? Oui, ça l’est quelque peu, sans doute, mais encore une fois il s’agit de la partie la plus contournée du mapping ORM. Prenez l’exemple que nous sommes en train de développer comme référence, et tout ira bien.
En conséquence, une modification de l’état
de l’association au niveau d’un artiste ne déclenchera pas
d”update dans la base de données. En d’autres termes, l’instruction
// Alfonso Cuaron a réalisé Gravity
cuaron.addFilmsRealise(gravity);
ne sera pas synchronisée dans la base, et rendue persistante. On a sauvé
un update, mais introduit une source d’incohérence. Une petite
modification de la méthode addFilmsRealises() suffit à prévenir
le problème.
public void addFilmsRealise(Film f) {
f.setRealisateur(this);
filmsRealises.add(f) ;
}
L’astuce consiste à appeler setRealisateur() pour garantir la mise à jour dans
la base dans tous les cas.
En résumé#
Il est sans doute utile de résumer ce qui précède. Voici donc la méthode
recommandée pour une association un à plusieurs.
Nous prenons comme guide l’association entre les films et leurs réalisateurs. Film
est du côté plusieurs (un réalisateur met en scène plusieurs films), Artiste
du côté un (un film a un metteur en scène). Dans la base
relationnelle, c’est du côté plusieurs que l’on trouve la clé étrangère.
Du côté « plusieurs »
On donne la spécification du mapping avec la base de données. Les annotations
sont @ManyToOne et @JoinColumn. Par exemple.
@ManyToOne
@JoinColumn (name="id_realisateur")
private Artiste realisateur;
Dans le jargon ORM, ce côté est « responsable » de la gestion du mapping.
Du côté « un »
On indique avec quelle classe responsable on est associé, et quelle propriété dans cette
classe représente l’association. Aucune référence directe à la base de données n’est faite.
L’annotation est @OneToMany avec l’option mappedBy qui indique que la
responsabilité de l’association est déléguée à la classe référencée, dans laquelle
l’association elle-même est représentée par la valeur de l’attribut mappedBy. Par exemple:
@OneToMany(mappedBy="realisateur")
private Set<Film> filmsRealises = new HashSet<Film>();
Hibernate inspectera la propriété realisateur dans la classe responsable
pour déterminer les informations de jointure si nécessaire.
Les accesseurs
Du côté plusieurs, les accesseurs sont standards. Pour la classe Film.
public void setRealisateur(Artiste a) {realisateur = a;}
public Artiste getRealisateur() {return realisateur;}
et pour la classe Artiste, on prend soin d’appeler l’accesseur de la classe responsable
pour garantir la synchronisation avec la base et la cohérence du graphe.
public void addFilmsRealise(Film f) {
f.setRealisateur(this);
filmsRealises.add(f) ;
}
public Set<Film> getFilmsRealises() {return filmsRealises;}
Et voilà! Dans ces conditions, voici le code pour créer une association.
public void insertFilm() {
session.beginTransaction();
Film gravity = new Film();
gravity.setTitre("Gravity");
gravity.setAnnee(2013);
Genre genre = new Genre();
genre.setCode("Science-fiction");
gravity.setGenre(genre);
Artiste cuaron = new Artiste();
cuaron.setPrenom("Alfonso");
cuaron.setNom("Cuaron");
// Alfonso Cuaron a réalisé Gravity
cuaron.addFilmsRealise(gravity);
// Sauvegardons dans la base
session.save(gravity);
session.save(cuaron);
session.getTransaction().commit();
}
L’association est réalisée des deux côtés en java par un seul appel à la méthode
addFilmsRealises(). Notez également qu’il reste nécessaire
de sauvegarder individuellement le film et l’artiste. Nous pouvons gérer cela
avec des annotations Cascade, mais vous avez probablement assez de concepts à avaler
pour l’instant.
Lisez et relisez ce qui précède. Pas de panique, il suffit de reproduire la même construction à chaque fois. Bien entendu c’est plus facile si l’on a compris le pourquoi et le comment.
Exercice: vérifier qu’Hibernate ne génére plus de requête redondante.
Modifiez insertFilm() comme indiqué, et consultez les requêtes Hibernate pour vérifier
qu’un seul update est effectué.
Que se passe-t-il si l’application appelle directement setRealisateur() et
pas addFilmsRealise()? Que faudrait-il faire?
S4: Associations plusieurs-à-plusieurs#
Supports complémentaires :
Nous en venons maintenant aux associations de type « plusieurs-à-plusieurs », dont deux représentants apparaissent dans le modèle de notre base webscope:
un film a plusieurs acteurs; un acteur joue dans plusieurs films;
un internaute note plusieurs films; un film est noté par plusieurs internautes.
Quand on représente une association plusieurs-plusieurs en relationnel, l’association
devient une table dont la clé est la concaténation des clés des deux entités de l’association.
C’est bien ce qui a été fait pour cette base: une table Role représente la première
association avec une clé composée (id_film, id_acteur) et une table Notation
représente la seconde avec une clé (id_film, email). Et il faut noter
de plus que chaque partie de la clé est elle-même une clé étrangère.
On pourrait généraliser la règle à des associations ternaires, et plus. Les clés deviendraient très compliquées et le tout deviendrait vraiment difficile à interpréter. La recommandation dans ce cas est de promouvoir l’association en entité, en lui donnant un identifiant qui lui est propre.
Note
Même pour les associations binaires, il peut être justicieux de
transformer toutes les associations plusieurs-plusieurs en entité,
avec deux associations un-plusieurs vers les entités originales. On aurait donc une
entité Role et une entité Notation (chacune avec un identifiant). Cela
simplifierait le mapping JPA qui, comme on va le voir, est un peu compliqué.
On trouve de nombreuses bases (dont la nôtre) incluant la représentation d’associations plusieurs-plusieurs avec clé composée. Il faut donc savoir les gérer. Deux cas se présentent en fait:
l’association n’est porteuse d’aucun attribut, et c’est simple;
l’association porte des attributs, et ça se complique un peu.
Nos associations sont porteuses d’attributs, mais nous allons quand même traiter les deux cas par souci de complétude.
Premier cas: association sans attribut#
Dans notre schéma, le nom du rôle d’un acteur dans un film est représenté
dans l’association (un peu de réflexion suffit à se convaincre qu’il
ne peut pas être ailleurs). Supposons pour l’instant que nous décidions de
sacrifier cette information, ce qui nous ramène au cas d’une association
sans attribut. La modélisation JPA/Hibernate est alors
presque semblable à celle des associations un-plusieurs. Voici
ce que l’on représente dans la classe Film.
@ManyToMany()
@JoinTable(name = "Role", joinColumns = @JoinColumn(name = "id_film"),
inverseJoinColumns = @JoinColumn(name = "id_acteur"))
Set<Artiste> acteurs = new HashSet<Artiste>();
public Set<Artiste> getActeurs() {
return acteurs;
}
C’est ce côté qui est « responsable » du mapping avec la base de données. On indique
donc une association @ManyToMany, avec une seconde annotation JoinTable
qui décrit tout simplement la table représentant l’association, joinColumn
étant la clé étrangère pour la classe courante (Film) et inverseJoinColumn
la clé étrangère vers la table représentant l’autre entité, Artiste.
Essayez de produire la requête SQL qui reconstitue l’association et vous verrez que toutes
les informations nécessaires sont présentes.
De l’autre côté, c’est plus simple encore puisqu’on ne répète pas la description
du mapping. On indique avec mappedBy qu’elle peut être trouvée dans la
classe Film. Ce qui donne, pour la filmographie d’un artiste:
@ManyToMany(mappedBy = "acteurs")
Set<Film> filmo;
public Set<Film> getFilmo() {
return filmo;
}
C’est tout, il est maintenant possible de naviguer d’un film vers ses acteurs et
réciproquement. L’interprétation de mappedBy est la même que dans le cas
des associations un-plusieurs.
Exercice: afficher tous les acteurs d’un film.
Reprenez l’action qui affiche les films, et ajoutez la liste des acteurs. De même, pour la liste des artistes, affichez les films dans lesquels ils ont joué.
Second cas: association avec attribut#
Maintenant, nous reprenons notre base, et nous aimerions bien accéder au nom
du rôle, ce qui nécessite un accès à la table Role representant l’association.
Nous allons représenter dans notre modèle JPA cette association comme
une @Entity, avec des associations un à plusieurs vers, respectivement,
Film et Artiste, et le tour est joué.
Oui, mais… nous voici confrontés à un problème que nous n’avons pas encore
rencontré: la clé de Role est composée de deux attributs. Il va donc falloir
tout d’abord apprendre à gérer ce cas.
Nous avons fait déjà un premier pas dans ce sens en étudiant les
composants (vous vous souvenez, les adresses?). Une clé en Hibernate
se représente par un objet. Quand cet objet est une valeur d’une
classe de base (Integer, String), tout va bien. Sinon,
il faut définir cette classe avec les attributs constituant la clé.
En introduisant un nouveau niveau de granularité dans la représentation
d’une entité, on obtient bien ce que nous avons appelé précédemment
un composant.
La figure Gestion d’un identifiant composé montre ce que nous allons créer. La
classe Role est une entité composée d’une clé et d’un attribut,
le nom du rôle. La clé est une instance d’une classe RoleId
constituée de l’identifiant du film et de l’identifiant de l’acteur.
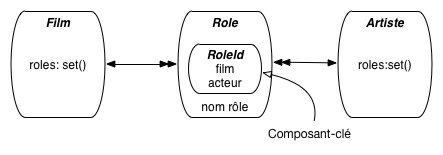
Figure 2: Gestion d’un identifiant composé#
Voici la méthode illustrée par la pratique. Tout d’abord nous créons cette classe représentant la clé.
package modeles.webscope;
import javax.persistence.*;
@Embeddable
public class RoleId implements java.io.Serializable {
/**
*
*/
private static final long serialVersionUID = 1L;
@ManyToOne
@JoinColumn(name = "id_acteur")
private Artiste acteur;
public Artiste getActeur() {
return acteur;
}
public void setActeur(Artiste a) {
this.acteur = a;
}
@ManyToOne
@JoinColumn(name = "id_film")
private Film film;
public Film getFilm() {
return film;
}
public void setFilm(Film f) {
this.film = f;
}
}
Notez que ce n’est pas une entité, mais un composant annoté avec @Embeddable
(reportez-vous à la section sur les composants si vous avez un doute). Pour le
reste on indique les associations @ManyToOne de manière standard.
Important
une classe dont les instances vont servir d’identifiants
doit hériter de serializable, la raison - technique - étant
que des structures de cache dans Hibernate doivent être sérialisées
dans la session, et que ces structures indexent les objets par la clé.
Voici maintenant l’entité Role.
package modeles.webscope;
import javax.persistence.*;
@Entity
public class Role {
@Id
RoleId pk;
public RoleId getPk() {
return pk;
}
public void setPk(RoleId pk) {
this.pk = pk;
}
@Column(name="nom_role")
private String nom;
public void setNom(String n) {nom= n;}
public String getNom() {return nom;}
}
On indique donc que l’identifiant est une instance de RoleId. On la
nomme pk pour primary key, mais le nom n’a pas d’importance. La
classe comprend de plus les attributs de l’association.
Et cela suffit. On peut donc maintenant accéder à une instance r de rôle,
afficher son nom avec r.nom et même accéder au film et à l’acteur
avec, respectivement, r.pk.film et r.pk.acteur. Comme cette
dernière notation peut paraître étrange, on peut ajouter le code
suivant dans la classe Role qui implante un racourci vers
le film et l’artiste.
public Film getFilm() {
return getPk().getFilm();
}
public void setFilm(Film film) {
getPk().setFilm(film);
}
public Artiste getActeur() {
return getPk().getActeur();
}
public void setActeur(Artiste acteur) {
getPk().setActeur(acteur);
}
Maintenant, si r est une instance de Role, r.film et r.acteur
désignent respectivement le film et l’acteur.
Il reste à regarder comment on code l’autre côté de l’association. Pour le film, cela donne:
@OneToMany(mappedBy = "pk.film")
private Set<Role> roles = new HashSet<Role>();
public Set<Role> getRoles() {
return this.roles;
}
public void setRoles(Set<Role> r) {
this.roles = r;
}
Seule subtilité: le mappedBy indique un chemin qui part de Role,
passe par la propriété pk de Role, et arrive à la propriété
film de Role.pk. C’est là que l’on va trouver la définition
du mapping avec la base, autrement le nom de la clé
étrangère qui référence un film. Même chose du côté des artistes:
@OneToMany(mappedBy = "pk.acteur")
private Set<Role> roles = new HashSet<Role>();
public Set<Role> getRoles() {
return this.roles;
}
public void setRoles(Set<Role> r) {
this.roles = r;
}
Exercice: affichez tous les rôles
Créez une action qui affiche tous les rôles, avec leur film et leur artiste.
Nous avons fait un bon bout de chemin sur la compréhension du mapping JPA. Nous arrêtons là pour l’instant afin de bien digérer tout cela. Voici un exercice qui vous permettra de finir la mise en pratique.
Exercice: compléter le mapping de la base webscope
Vous en savez maintenant assez pour compléter la description du mapping O/R de la base webscope. Une fois cela accompli, vous devriez pouvoir créer une action qui affiche tous les films avec leur metteur en scène, leurs acteurs et les rôles qu’ils ont joué. Vous devriez aussi pouvoir afficher les internautes, les notes qu’ils ont données et à quels films.
Résumé: savoir et retenir#
À l’issue de ce chapitre,, assez dense, vous devez être en mesure de définir le mapping ORM pour la plupart des bases de données, une exception (rare) étant la représentation de l’héritage, pour lequel les bases relationnelles ne sont pas adaptées, mais que l’on va trouver potentiellement dans la modélisation objet de l’application. Il faut alors savoir produire une structure de base de données adaptée, et la mapper vers les classes de l’application. C’est ce que nous verrons dans le prochain chapitre.
Il resterait encore des choses importantes à couvrir pour être complets sur le sujet. Entre autres:
les méthodes
equals()ethashCode()sont importantes pour certaines classes; il faudrait les implanter;des options d’annotation, dont celles qui indiquent comment propager la persistence en cascade, méritent d’être présentées.
Concentrez-vous pour l’instant sur les connaissances acquise dans le présent chapitre, et gardez en mémoire que vous n’êtes pas encore complètement outillés pour faire face à des situations relativement marginales. Pour consolider vos acquis, il serait sans doute judicieux de prendre un schéma de base de données que vous connaissez et de produire le mapping adapté.