2. Applications Web dynamiques#
Commençons par une courte introduction au Web et à la programmation Web, limitée aux pré-requis indespensables pour comprendre la suite du cours. Vous trouverez facilement sur le Web beaucoup de documentation plus étendue sur ce sujet, avec notamment une perspective plus large sur les autres langages (CSS, JavaScript) intervenant dans la réalisation d’une application web. Les lecteurs déjà familiers avec ces bases peuvent sauter ce chapitre sans dommage.
S1: Bases sur le fonctionnement du Web#
Supports complémentaires :
Le World-Wide Web (ou WWW, ou Web) est un très grand système d’information réparti sur un ensemble de machines connectés par le réseau Internet. Ce système est essentiellement constitué de documents hypertextes et de documents multimedia: textes, images, sons, vidéos, etc. Le Web propose aussi des services ou des modes de communication entre machines permettant d’effectuer des calculs répartis ou des échanges d’information sans faire intervenir d’utilisateur : le cours n’aborde pas ces aspects.
Chaque machine propose un ensemble plus ou moins important de documents qui sont transmis sur le réseau par l’intermédiaire d’un programme serveur. Le plus connu de ces programmes est peut-être Apache, un serveur Open source très couramment utilisé pour des sites simples (Blogs, sites statiques). D’autres programmes, plus sophistiqués, sont conçus pour héberger des applications Web complexes et sont justement désignés comme des serveurs d’application (par exemple, Glassfish, ou des logiciels propriétaires comme WebSphere).
Dans tous les cas, ce programme serveur dialogue avec un programme client qui peut être situé n’importe où sur le réseau. Le programme client prend le plus souvent la forme d’un navigateur, grâce auquel un utilisateur du Web peut demander et consulter très simplement des documents. Les navigateurs les plus connus sont Firefox, Internet Explorer, Safari, Opera, etc.
Fonctionnement#
Le dialogue entre un programme serveur et un programme client s’effectue selon des règles précises qui constituent un protocole. Le protocole du Web est HTTP.
Tout site web est constitué, matériellement, d’une machine connecté à l’Internet équipée du programme serveur tournant en permanence sur cet ordinateur. Le programme serveur est en attente de requêtes transmises à son attention sur le réseau par un programme client. Quand une requête est reçue, le programme serveur l’analyse afin de déterminer quel est le document demandé, recherche ce document et le transmet au programme client. Un autre type important d’interaction consiste pour le programme client à demander au programme serveur d’exécuter un programme, en fonction de paramètres, et de lui transmettre le résultat.
La figure Architecture Web illustre les aspects essentiels d’une communication web pour l’accès à un document. Elle s’effectue entre deux programmes. La requête envoyée par le programme client est reçue par le programme serveur. Ce programme se charge de rechercher le document demandé parmi l’ensemble des fichiers auxquels il a accès, et transmet ce document.
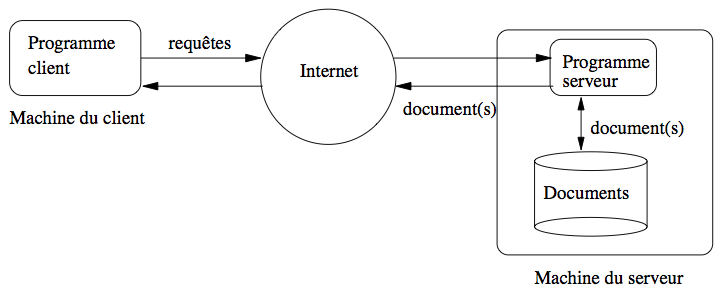
Figure 1: Architecture Web#
Nous serons amenés à utiliser un serveur web pour programmer notre application.
Apache est peut-être le serveur web le plus répandu; il est notamment très bien adapté à l’association avec le langage PHP.
Tomcat est un serveur d’application simple dédié à l’exécution d’application Web java; c’est lui que nous utiliserons pour notre développement.
Dans tout ce qui suit, le programme serveur sera simplement désigné par le terme serveur ou par le nom du programme particulier que nous utilisons, Apache ou Tomcat. Les termes navigateur et client désigneront tous deux le programme client. Enfin le terme utilisateur sera réservé à la personne physique qui utilise un programme client.
Le protocole HTTP#
HTTP, pour HyperText Transfer Protocol, est un protocole extrêmement simple, basé sur TCP/IP, initialement conçu pour échanger des documents hypertextes. HTTP définit le format des requêtes et des réponses. Voici par exemple une requête envoyée à un serveur Web:
GET /myResource HTTP/1.1
Host: www.example.com
Elle demande une ressource nommée myResource au serveur www.example.com.
Et voici une possible réponse à cette requête:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
<html>
<head><title>myResource</title></head>
<body><p>Hello world!</p></body>
</html>
Un message HTTP est constitué de deux parties: l’entête et le corps, séparées par une ligne blanche. La réponse montre que l’entête contient des informations qualifiant le message. La première ligne par exemple indique qu’il s’agit d’un message codé selon la norme 1.1 de HTTP, et que le serveur a pu correctement répondre à la requête (code de retour 200). La seconde ligne de l’entête indique que le corps du message est un document HTML encodé en UTF-8.
Le programme client qui reçoit cette requête affiche le corps du message en fonction des informations contenues dans l’entête. Si le code HTTP est 200 par exemple, il procède à l’affichage. Un code 404 indique une ressource manquante, une code 500 indique une erreur sévère au niveau du serveur, etc.
D’autres aspects du protocole HTTP incluent la protection par mot de passe, la négociation de contenu (le client indique quel type de document il préfère recevoir), des cookies, informations déposées côté client pour mémoriser les séquences d’échanges (sessions), etc. Le contenu du cours n’étant pas centré sur la programmation web, nous n’aurons à utiliser que des notions simples.
Les URLs#
Les documents, et plus généralement les ressources sur le Web, sont identifiés par une URL (Uniform Resource Locator) qui encode toute l’information nécessaire pour trouver la ressource et aller la chercher. Cet encodage prend la forme d’une chaîne de caractères formée selon des règles précises illustrées par l’URL fictive suivante:
https://www.example.com:443/chemin/vers/doc?nom=orm&type=latex#fragment
Ici, https est le protocole qui indique la méthode d’accès à la ressource.
Le seul protocole que nous verrons est HTTP (le s indique une variante
de HTTP comprenant un encryptage des échanges). L’hôte (hostname)
est www.example.com. Un des services du Web (le DNS) va convertir ce nom
d’hôte en adresse IP, ce qui permettra d’identifier la machine serveur qui
héberge la ressource.
Note
Quand on développe une application, on la teste
souvent localement en utilisant sa propre machine de développement
comme serveur. Le nom de l’hôte est alors localhost, qui
correspond à l’IP 127.0.0.1.
La machine serveur communique avec le réseau sur un ensemble de ports, chacun correspondant à l’un des services gérés par le serveur. Pour le service HTTP, le port est par défaut 80, mais on peut le préciser, comme sur l’exemple précédent, où il vaut 443.
Note
Par défaut, le serveur Tomcat est configuré pour écouter sur le port 8080.
On trouve ensuite le chemin d’accès à la ressource, qui suit la syntaxe d’un chemin d’accès à un fichier dans un système de fichiers. Dans les sites simples, « statiques », ce chemin correspond de fait à un emplacement physique vers le fichier contenant la ressource. Dans des applications dynamiques, les chemins sont virtuels et conçus pour refléter l’organisation logique des ressources offertes par l’application.
Après le point d’interrogation, on trouve la liste des paramètres (query string) éventuellement transmis à la ressource. Enfin, le fragment désigne une sous-partie du contenu de la ressource. Ces éléments sont optionnels.
Le chemin est lui aussi optionnel, auquel cas l’URL désigne la racine du site web. Les URL peuvent également être relatives (par opposition aux URLs absolues décrites jusqu’ici), quand le protocole et l’hôte sont omis. Une URL relative est interprétée par rapport au contexte (par exemple l’URL du document courant).
Le langage HTML#
Les documents échangés sur le Web peuvent être de types très divers. Le principal type est le document hypertexte, un texte dans lequel certains mots, ou groupes de mots, sont des liens, ou ancres, référençant d’autres documents. Le langage qui permet de spécifier des documents hypertextes, et donc de fait le principal langage du Web, est HTML.
La présentation de HTML dépasse le cadre de ce cours. Il existe de très nombreux tutoriaux sur le Web qui décrivent le langage (y compris XHTML, la variante utilisée ici). Il faut noter que HTML est dédié à la présentation des documents d’un site, et ne constitue pas un langage de programmation. Son apprentissage (au moins pour un usage simple) est relativement facile. Par ailleurs, il existe de nombreux éditeurs de documents HTML qui facilitent le travail de saisie des balises et fournissent une aide au positionnement (ou plus exactement au pré-positionnement puisque c’est le navigateur qui sera en charge de la mise en forme finale) des différentes parties du document (images, menus, textes, etc). Notre objectif dans ce cours n’étant pas d’aborder les problèmes de mise en page et de conception graphique de sites web, nous nous limiterons à des documents HTML relativement simples.
Par ailleurs on trouve gratuitement des templates HTML/CSS définissant le « style » d’un site. Nous verrons comment intégrer de tels templates à notre application dynamique.
Voici un exemple simple du type de document HTML que nous allons
créer. Notez les indications en début de fichier
(DOCTYPE) qui
déclarent le contenu comme devant être conforme à
la norme XHTML:
<?xml version="1.0" encoding="utf8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr" >
<head>
<title>Gestion de la persistance dans les applications</title>
<link rel='stylesheet' href="template.css" type="text/css"/>
</head>
<body>
<h1>Cours Frameworks/ORM</h1>
<hr/>
Ce cours aborde les ORM comme
<a href="http://hibernate.org">Hibernate</a>,
dans le cadre du développement d'aplications modernes
construites avec des <i>frameworks</i>.
</body>
</html>
La variante utilisée dans nos exemples est XHTML, une déclinaison de HTML conforme aux règles de constitution des documents XML. XHTML impose des contraintes rigoureuses, ce qui est un atout pour créer des sites portables et multi-navigateurs. Je vous conseille d’ailleurs d’équiper votre navigateur Firefox d’un validateur HTML qui vous indiquera si vos pages sont bien formées.
Important
Tous nos documents doivent être encodés en UTF 8, un codage adapté aux langues européennes. Il faut utiliser un éditeur qui permet de sauvegarder les documents dans ce codage: dans notre cas ce sera Eclipse.
Exercice: quelques manipulations utiles avec Firefox.
Le navigateur que nous allons utiliser par défaut est Firefox qui a entre autres l’avantage d’être disponible (gratuitement) sur toutes les plateformes. Vous pouvez le télécharger et l’installer à partir de http://mozilla.org. Firefox peut être « étendu » avec des composants de toute sorte (plugins). Nous vous recommandons l’installation du plugin Web Developer: cette extension vous aide à analyser l’environnement et le statut de votre navigateur. Vous pouvez le récupérer à l’adresse https://addons.mozilla.org/fr/firefox/addon/web-developer/.
Une fois installé, Web developer se présente sous la forme d’une barre d’outils dans votre navigateur, ou dans un menu contextuel en cliquant avec le bouton droit. Voici maintenant quelques manipulations utiles pour aller plus loin que l’affichage de pages web (à vous de fouiller dans les menus Firefox et Web developer pour trouver comment effectuer chaque manipulation).
Affichage du code source de la page. Allez sur n’importe quel site et consultez le code source HTML. Avec Web Developer, l’option « Voir le code source généré » vous montre le code généré localement par le navigateur, par exemple par exécution de Javascript.
Consultations des cookies. Les cookies sont des informations (permettant notamment de vous identifier) déposées par les sites dans votre navigateurs. Il est instructif de les consulter…
Entêtes HTTP. Analysez les informations transmises dans l’entête HTTP du document que vous affichez.
CSS. Jetez un oeil au code CSS qui sert à la mise en page du document affiché, et effectuez quelques modifications avec Web explorer.
Il ne s’agit que d’une liste indicative. Nous vous invitons à consacrer 20 mns à explorer les autres outils proposés par Web explorer: cela peut s’avérer un gain de temps quand vous aurez à résoudre un problème pour votre application web plus tard.
Exercice: installation et utilisation de cURL.
cURL est un outil permettant de soumettre directement des requêtes HTTP à partir d’une console.
Vous pouvez le récupérer sur le site http://curl.haxx.se/. Une fois installé, la commande curl
sert à transmettre des requêtes HTTP. Voici par exemple comment effectuer un GET de la
page d’accueil d’un site:
curl -X GET http://www.cnam.fr
L’option -v donne le détail des messages HTTP transmis et reçus. Voici quelques suggestions:
Effectuez la requête ci-dessus avec l’option
-vet analysez les entêtes HTTP de la requête et de la réponse.Utilisez cURL pour accéder à des services qui fournissent des données dans un format structuré en réponse à des requêtes HTTP. Par exemple:
Les services de
freegeoip/net`. Exemple:curl http://freegeoip.net/json/62.147.199.138Un service de prévision météo, comme par exemple
OpenWeatherMap. Exemple:curl api.openweathermap.org/data/2.5/weather?q=London,ukEtudiez les paramètres passés dans l’URL et tentez de faire des changements. Notez que le format de réponse n’est plus HTML, qui peut être vu comme un cas particulier (mais le plus courant) d’utilisation des protocoles du Web.
S2: Applications Web et frameworks#
Supports complémentaires :
La programmation web permet de dépasser les limites étroites des pages HTML statiques dont le contenu est stocké dans des fichiers, et donc fixé à l’avance. Le principe consiste à produire les documents HTML par une application intégrée au serveur web. Cette application reçoit des requêtes venant d’un programme client, sous la forme d’URL associées à des paramètres et autres informations transmises dans le corps du message (cf. les services Web que vous avez dû étudier ci-dessus). Le contenu des pages est donc construit à la demande, dynamiquement.
Architecture#
La figure Architecture d’une application Web illustre les composants de base d’une application web. Le navigateur (client) envoie une requête (souvent à partir d’un formulaire HTML) qui est plus complexe que la simple demande de transmission d’un document. Cette requête déclenche une action dans l’application hébergée par le serveur référencé par son URL. L’exécution de l’action se déroule en trois phases:
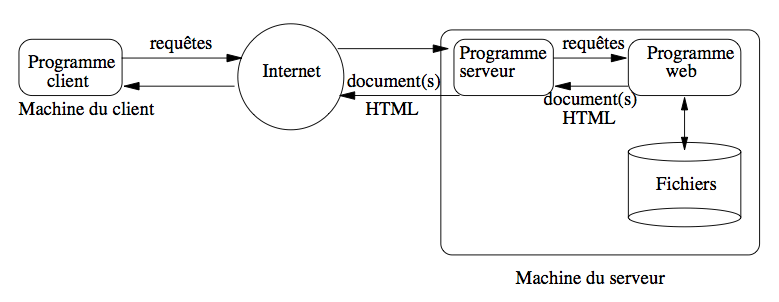
Figure 2: Architecture d’une application Web#
Constitution de la requête par le client: le navigateur construit une URL contenant le nom du programme à exécuter, accompagné, le plus souvent, de paramètres saisis par l’internaute dans un formulaire;
Réception de la requête par le serveur: le programme serveur récupère les informations transmises par le navigateur, et déclenche l’exécution du programme, en lui fournissant les paramètres reçus;
Transmission de la réponse: le programme renvoie le résultat de son exécution au serveur sous la forme d’un document HTML, le serveur se contentant alors de faire suivre au client.
Le programme web est soit écrit dans un langage spécialisé (comme PHP) qui s’intègre étroitement au programme serveur et facilite le mode de programmation particulier aux applications web, soit écrit dans un langage généraliste comme Java, mais accompagné dans ce cas d’un ensemble de composants facilitant considérablement la réalisation des applications Web (comme JEE, Java Enterprise Edition). En particulier l’environnement de programmation doit offrir une méthode simple pour récupérer les paramètres de la requête, et autres informations (entêtes) transmis par HTTP. Il est alors libre de faire toutes les opérations nécessaires pour satisfaire la demande (dans la limite de ses droits d’accès bien sûr). Il peut notamment rechercher et transmettre des fichiers ou des images, effectuer des contrôles, des calculs, créer des rapports, etc. Il peut aussi accéder à une base de données pour insérer ou rechercher des informations. C’est ce dernier type d’utilisation (extrêmement courant) que nous étudions dans ce cours.
Et la base de données?#
La plupart des applications Web ont besoin de s’appuyer sur une base de données pour stocker des données persistantes: comptes clients, catalogues, etc. L’application Web, qu’elle soit en Java, PHP ou n’importe quel autre langage, fait donc intervenir un autre acteur, le serveur de données (le plus souvent un système relationnel comme MySQL), et communique avec lui par des requêtes SQL.
Dans le cas de PHP par exemple,
il est possible à partir d’un script de se connecter
à un serveur mysqld pour récupérer des données dans la base
que l’on va ensuite afficher dans des documents HTM.
D’une certaine manière, PHP permet de faire d’Apache
un client MySQL, ce qui aboutit à l’architecture
de la figure Architecture d’une application Web avec base de données.
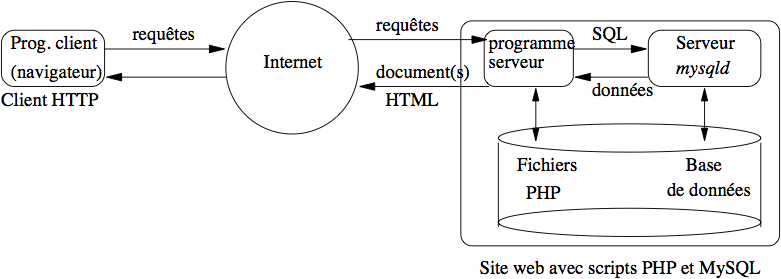
Figure 3: Architecture d’une application Web avec base de données#
Il s’agit d’une architecture à trois composantes, chacune réalisant une des trois tâches fondamentales d’une application.
le navigateur constitue l’interface graphique dont le rôle est de permettre à l’utilisateur de visualiser et d’interagir avec l’information;
MySQL est le serveur de données;
enfin l’ensemble des fichiers PHP contenant le code d’extraction, traitement et mise en forme des données est le serveur d’application, associé à Apache qui se charge de transférer les documents produits sur l’Internet.
Architecture et développement d’applications Web#
La présentation qui précède n’est qu’une introduction extrêmement sommaire au monde de la conception et de la réalisation d’applications Web. À chaque niveau, on trouve une multitude de détails à gérer, relatifs aux protocoles d’échange, aux langages utilisés, à l’interaction des différents composants, etc. Pour faire simple à ce stade, et sur la base de ce qui est décrit ci-dessus, on peut noter des particularités essentielles qui caractérisent les applications Web:
Ce sont des applications interactives et distribuées, à base d’échanges de documents hypertextes avec un protocole spécial, HTTP;
Plusieurs langages sont impliqués: au moins HTML, SQL, et le langage de programmation de l’application (plus éventuellement bien d’autres comme Javascript, les CSS, etc.);
une application Web est ouverte sur le monde, ce qui soulève de redoutables problèmes de protection contre les messages nocifs, qu’ils soient volontaires ou non.
Ces particularités soulèvent des questions délicates relatives à l’architecture de l’application. Même si cette notion reste abstraite à ce stade, on peut dire qu’elle revient à trouver la meilleure manière de coordonner des composants chargés de rôles très différents (recevoir des requêtes HTTP, transmettre des réponses HTTP, accéder à la base de données), sans aboutir à un mélange inextricable de différents langages et fonctionnalités dans une même action.
Heureusement, cette problématique de l’architecture d’une application a été étudiée depuis bien longtemps, et un ensemble de bonnes pratiques, communément admises, s’est dégagé. De plus, ces bonnes pratiques sont encouragées, voire forcées, par des environnements de programmation dédiés aux applications Web, les fameux frameworks.
La partie qui suit est une courte introduction à la notion de framework. Elle est nécessairement abstraite et peut sembler extrêmement obscure quand on la rencontre hors de tout contexte. Pas d’affolement: essayez de vous imprégner des idées principales et de saisir l’essentiel. Les choses se clarifieront considérablement quand nous aurons l’occasion de mettre les idées en pratique.
Les frameworks de développement#
Un framework (littéralement, un cadre de travail), c’est un ensemble d’outils logiciels qui normalisent la manière de structurer et coder une application. Le terme regroupe trois notions distinctes et complémentaires
Une conception générique: une architecture, un modèle, une approche générique pour répondre à un besoin ou problème (générique) donné.
La généricité garantit la portée universelle (dans le cadre du problème étudié, par exemple le développement d’applications web) de la conception. C’est une condition essentielle, sinon le framework n’est pas utilisable.
- Des bonnes pratiques: il s’agit, de manière moins formelle que le conception, d’un
ensemble de règles, de conventions, de recommandations, de patrons (design patterns), élaborés et affinés par l’expérience d’une large communauté, pour mettre en oeuvre la conception.
Les bonnes pratiques capitalisent sur l’expérience acquise. Leur adoption permet d’éviter des erreurs commises dans le passé, et d’uniformiser la production du logiciel.
Et enfin (surtout?), un environnement logiciel qui aide le développeur – et parfois le force – à adopter l’architecture/modèle et respecter les règles.
La partie logicielle d’un framework fournit un support pour éviter des tâches lourdes et répétitives (par exemple le codage/décodage des messages HTTP), ce qui mène à un gain considérable en productivité.
L’adoption d’un framework, parce qu’il correspond à une forme de normalisation du développement, facilite considérablement le travail en équipe.
Note
On parle à tort et à travers de frameworks, notamment pour désigner des choses qui n’en sont pas (librairies, composants logiciels). Nous allons essayer d’être précis!
Caractérisation d’un framework#
Un framework se distingue d’autres formes de composants logiciels (bibliothèques de fonction par exemple) par une caractéristique fondamentale, l’inversion de contrôle. Dans une application « régulière », le contrôle (c’est-à-dire le pilotage du flux de traitement en fonction des événements rencontrés) est géré par l’application elle-même. Elle décide par exemple d’afficher un questionnaire, puis de récupérer les réponses sur déclenchement de l’utilisateur, de les traiter, et enfin de produire un résultat. En chemin, des fonctionnalités externes, prêtes à l’emploi, peuvent être appelées, mais cela se fait sur décision de l’application elle-même. C’est le scénario (classique) illustré par la partie gauche de la figure L’inversion de contrôle.
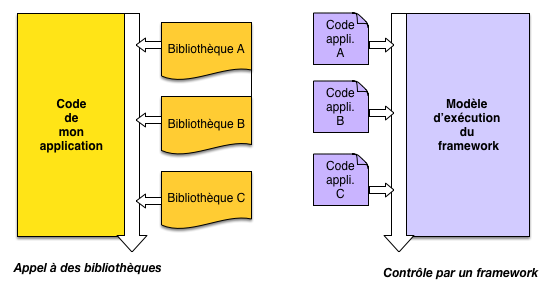
Figure 4: L’inversion de contrôle#
Contrairement à une bibliothèque, un framework est un composant actif qui contrôle lui-même le déroulement de l’application, selon un modèle générique pré-établi. L’application qui utilise le framework se contente d’injecter des composants qui vont être utilisés le moment venu par la framework en fonction du déroulement des interactions.
Cela paraît abstrait? Ça l’est, et cela explique deux aspects des frameworks, l’un négatif et l’autre positif:
Côté négatif: l’apprentissage (surtout initial) peut être long car le framework est une sorte de boîte noire à laquelle on confie des composants sans savoir ce qu’il va en faire. C’est - entre autres - parce que le contrôle échappe au développeur de l’application qu’il est difficile de s’y retrouver (au début).
Côté positif: l’inversion de contrôle signifie que toute une partie du comportement de l’application n’a plus jamais à être implantée, ce qui constitue un gain de productivité considérable. Entre autres avantages, un framework nous décharge de tâches lourdes, répétitives, et sources d’erreur de programmation ou de conception.
L’inversion de contrôle n’est possible que pour des classes d’application obéissant à des comportements particuliers. C’est le cas par exemple des applications Web, dont le comportement est un cycle effectuant répétitivement la réception d’une requête HTTP, le traitement de cette requête, et la réponse (en HTTP) le plus souvent sous la forme d’une page HTML. Les frameworks web automatisent la gestion de ces cycles.
Pour conclure cette brève présentation sur un exemple, supposons que l’on veuille construire des questionnaires en ligne, avec fourniture d’un rapport chaque fois que le formulaire est rempli par un internaute. Une approche basique consiste à construire chaque formulaire par programmation avec des instructions du type:
out.println "<form action='...'>";
out.println "<input type='text' name='email'>Votre email</input>";
out.println "<input type='text' name='nom'>Votre nom</input>";
out.println "</form>";
Puis, il faut implanter du code pour récupérer les réponses et les traiter. Quelque chose comme:
for each (reponse in reponses) {
// Il faut comprendre à quelle question correspond la réponse
// Il faut ajouter la question et la réponse dans un joli rapport
}
Il est évident (?) qu’en repartant de zéro pour chaque questionnaire, on va produire beaucoup de code répétitif, ce qui est le signe que la production de questionnaires obéit en fait à une approche générique:
construire des formulaires sous forme de question/réponses, en distinguant les différents types de réponse (libre/choix simple/choix multiple), leur caractère obligatoire ou non, etc.
soumettre les formulaires à des internautes, avec toutes le options souhaitables (retour, correction, validation, etc.)
enregistrer les réponses, produire un rapport (avec des mises en forme adaptées au besoin).
On en arrive donc rapidement à l’idée de construire un framework qui prendrait en charge tous les aspects génériques. Un tel framework devrait, s’il est bien conçu, permettre la construction d’un questionnaire en injectant simplement les questions à poser.
q = new Questionnaire(/* des options ...*/);
q->addChoixSimple ("Comment trouvez-vous ce cours?", ["Nul", "Moyen", "Parfait"]);
q->addQuestionLibre ("Avez-vous des commentaires ?");
q->render();
Résultat: un code minimal, tout en bénéficiant d’une implantation efficace et puissante des fonctionnalités génériques pour ce type d’application. Détaillons maintenant les deux type de framework auxquels nous allons nous consacrer pour, respectivement, les applications web et les applications persistantes.
Frameworks pour applications Web#
Le problème générique de base peut s’exprimer concisément ainsi: je veux créer une application Web dynamique qui produit des pages HTML créées à la volée en fonction de requêtes HTTP et alimentées par des informations provenant d’une base de données. Cette version basique se raffine considérablement si on prend en compte des besoins très courants (et donc formulables de manière générique également): authentification, intégration avec un modèle graphique, gestion des messages HTTP, multi-langages, etc.
Une conception générique courante pour répondre à ce problème est l’architecture Modèle-Vue-Contrôleur (MVC): mes pages HTML sont des vues, les interactions HTTP sont gérées par des contrôleurs, et la logique de mon application (persistante ou pas) est mon modèle. Le modèle MVC est sans doute le plus courant (mais pas le seul) pour le développement d’applications Web.
Les frameworks qui s’appuient sur ce modèle sont par exemple Symphony (PHP), Zend (PHP), Spring (Java), Grails (Groovy/Java), Django (Python), .NET (C#), Ruby on rails, etc. Outre le support des concepts de base (modèles, vues, contrôleurs), ils proposent tout un ensemble de bonnes pratiques et de conventions: le nommage des fichiers, des variables, organisation des répertoires, jusqu’à l’indentation, les commentaires, etc.
L’inversion de contrôle dans les frameworks web consiste à prendre entièrement en charge le cycle des échanges HTTP entre l’utilisateur (le client web) et l’application. En fonction de chaque requête, le framework détermine quel est le contrôleur à appliquer; ce contrôleur applique des traitements implantés dans la couche « modèle », et renvoie au framework une « vue », ce dernier se chargeant de la transmettre au client.
Frameworks de persistance#
Le problème (générique) peut se formuler comme suit: dans le cadre d’une application orientée-objet, je veux accéder à une base de données relationnelle. Les modes de représentation des données sont très différents: en objet, mes données forment un graphe d’entités dynamiques dotés d’un comportement (les méthodes), alors qu’en relationnel mes données sont organisées en tables indépendantes, et se manipulent avec un langage très particulier (SQL).
Cette différence de représentation soulève toutes sortes de problèmes quand on écrit une application qui doit « charger » des données de la base sous forme d’objet, et réciproquement stocker des objets dans une base. L’effet le plus concret est la lourdeur et la répétitivité du code pour effectuer ces conversions.
Le besoin (fort) est donc de rendre persistantes mes données objets, et « objectiser » mes données relationnelles. Les frameworks dits « de persistance » fournissent une méthode générique de transformation (mapping) des données relationnelles vers les données objet et vice-versa. Ils reposent là encore sur un ensemble de bonnes pratiques mises au point depuis des décennies de tâtonnement et d’erreurs. Ces bonnes pratiques s’appliquent à la représentation des associations, de l’héritage, à la traduction des navigations dans le graphe et requêtes sur les données, etc.
Ces frameworks sont dits ORM (Object-Relational Mapping). Les plus connus (courants) sont JPA/Hibernate (Java), JPA/EclipseLink (Java), Doctrine (PHP), CakePHP (PHP), ActiveRecords (Ruby), etc. Ils constituent le sujet principal du cours.
L’inversion de contrôle dans le cas des frameworks de persistance est la prise en charge de la conversion bi-directionnelle entre les objets et les tables, selon des directives de configuration / modélisation qui constituent les composants « injectés » dans le framework.
Etude: les différents types de framework
Cherchez sur le Web les principaux frameworks pour les classes d’application suivantes:
applications MVC (web)
applications persistantes (frameworks ORM)
application javascript (Ajax)
applications mobiles
Faites une synthèse présentée dans une page HTML, avec liens vers les sites que vous avez trouvées.
Etude: frameworks Web non-MVC
(Difficile). Existe-t-il d’autre modèles que le MVC pour des applications Web? Etudiez la question et trouvez quelques exemples de frameworks correspondant.
Résumé: savoir et retenir#
À ce stade, vous devez avoir acquis les notions suivantes:
Principes de base de HTTP: requête, réponse, entête, corps.
Forme des URL, signification des composants d’une URL.
Connaissance minimale de HTML; compréhension du rôle de CSS.
Vous devez également avoir compris comment fonctionne une application Web, dans le principe. Le développement de telles applications implique beaucoup de langages et protocoles. Pour organiser ce développement, des motifs de conceptions (design patterns) et des bonnes pratiques ont été mises au point. Des logiciels, dits frameworks, sont destinés à nous guider dans l’application des ces motifs et pratiques.
Vous devez être à l’aise dans l’utilisation du navigateur Firefox, et être capable d’inspecter le document HTML affiché, les CSS utilisés, etc.
Lisez et relisez à l’avenir la section consacrée aux frameworks: elle contient des concepts abstraits d’abord difficile. Vous devez vous fixer pour objectif de les comprendre progressivement. La notion de généricité est essentielle. La notion d’inversion de contrôle est utile pour comprendre ce qui distingue un framework d’un autre type de composant logicielle (mais on peut utiliser un framework sans la connaître). Le cours est essentiellement consacré aux frameworks de persistance, mais les intègre dans une approche MVC simplifiée. Ces concepts particuliers seront revus en détail ensuite.
Tout cela est abstrait? C’est justement le but du cours que de rendre ces avantages concrets. Le principal framework étudié sera celui assurant la connexion entre une application et une base de données (fonction dite « de persistance »), mais nous le placerons dans un contexte plus large, celui des frameworks de développement d’applications Web.